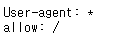
728x90
크롤링(crwaling) : 인터넷에서 데이터를 수집하여 받아오는 것
크롤러 : 크롤링을 하는 프로그램
파싱(parsing) : 데이터에서 필요한 내용만 추출하는 것
urllib 패키지
- 인터넷에서 데이터를 받아 오늘 기능들이 들어 있다.
BeautifulSoup 모듈
- 데이터를 추출(파싱)하는데 필요한 기능들이 들어 있다.
크롤링 시작 전 반드시 해당 사이트 url/robots.txt를 확인할 것
robots.txt : 인터넷에서 데이터를 수집하여 받아오는 것
robots.txt에서 반드시 확인할 3가지
- User-agent : 다음 규칙이 적용되는 로봇의 이름
- Disallow : 차단할 URL 경로
- Allow : 차단 된 상위 디렉토리의 하위 디렉토리에 있는 URL경로이며 차단 해제 할 디렉토리
네이버의 robots.txt

영화진흥위원회 robots.txt
urlib
더보기
from urllib.request import urlopen
url ="https://www.kofic.or.kr/"
html = urlopen(url)
print(html.read())BeautifulSoup
더보기
from bs4 import BeautifulSoup
from urllib.request import urlopen
url = "https://www.kofic.or.kr/"
html = urlopen(url)
bs_obj = BeautifulSoup(html.read(), "html.parser")
print(bs_obj)태그의 내용(text) 추출하기
더보기
# 태그 추출하기
import bs4
html_str= "<html><div>hello</div></html>"
bs_obj = bs4.BeautifulSoup(html_str,"html.parser")
print(bs_obj)
print(bs_obj.find("div"))
print(bs_obj.find("div").text)
findAll()
더보기
import bs4
html_str ="""
<html>
<body>
<ul>
<li>hello</li>
<li>bye</li>
<li>welcome</li>
</ul>
</body>
</html>
"""
bs_obj = bs4.BeautifulSoup(html_str, "html.parser")
ul = bs_obj.find("ul") # ul태그 찾음
lis = ul.findAll("li") # ul태그안의 li태그 전체 찾기
print(lis)
class 속성
더보기
import bs4
html_str ="""
<html>
<body>
<ul class= "greet">
<li>hello</li>
<li>bye</li>
<li>welcome</li>
</ul>
<ul class = "reply">
<li>ok</li>
<li>no</li>
<li>sure</li>
</ul>
</body>
</html>
"""
bs_obj = bs4.BeautifulSoup(html_str, "html.parser")
ul_reply = bs_obj.find("ul",{"class":"reply"})
print(ul_reply)
태그의 속성값 추출
더보기
import bs4
html_str ="""
<html>
<body>
<ul class="see">
<li><a href="https://www.kofic.or.kr">영화진흥위원회</a></li>
</ul>
<ul class ="eat">
<li><a href="http://www.price.go.kr/tprice/portal/main/main.do">한국소비자원참가격</a></li>
</ul>
</body>
</html>
"""
bs_obj = bs4.BeautifulSoup(html_str, "html.parser")
atag = bs_obj.find("a")
print(atag['href'])
특정 글자 뽑아내기 - 필요한 부분 뽑아내기
더보기
import urllib.request
import bs4
url = "https://www.kofic.or.kr/kofic/business/main/main.do"
html = urllib.request.urlopen(url)
bs_obj = bs4.BeautifulSoup(html, "html.parser")
top = bs_obj.find("div",{"class":"gnb"})
print(top)
728x90