CSV(Comma Separate Values)는 콤마(,)를 기준으로 나누어진 값이고 이해하면 된다.
csv 파일은 어디서나 사용할 수 있도록 텍스트 데이터를 사용한다.

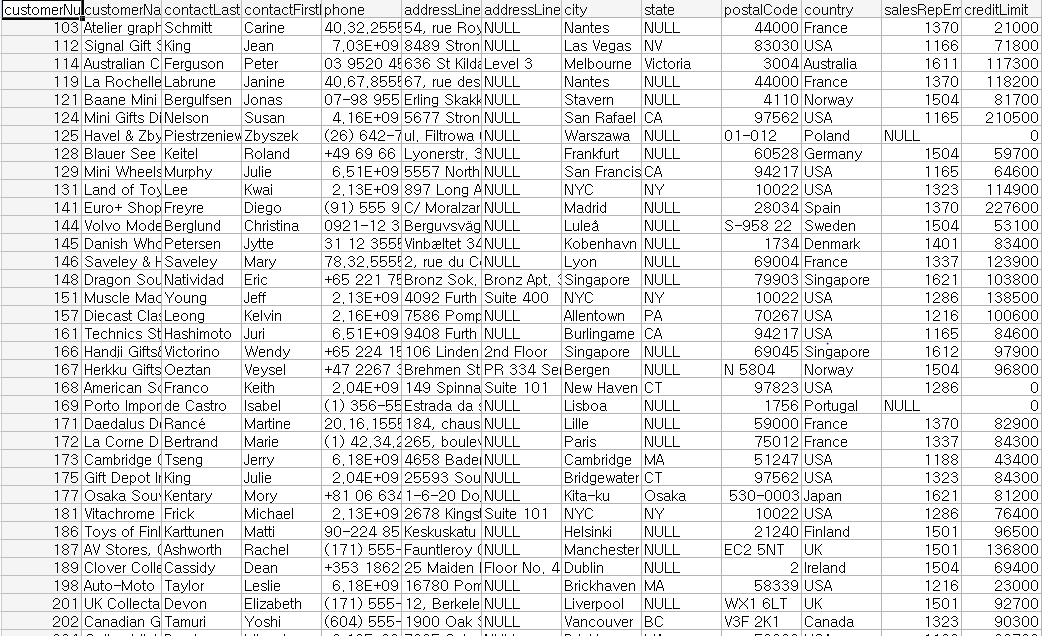
위의 데이터를 보면, 제일 상단에 필드(filed), 헤더(header) 또는 열 이름(column name)이라고 부르는 텍스트 데이터가 입력되었다. 각 데이터는 콤마로 나누어진다. 두 번째 줄부터는 각 필드의 실제 데이터가 있는데, 각 행위 데이터가 인슴턴스라고 이해하면 된다. 이러한 데이터를 행(row), 튜플(tuple), 인스턴스(instance)등으로 부른다. 데이터의 분류는 분류 기준이 되는 문자에 따라 TSV(Tab SeparateValues), SSV(Single-blank Separate Values) 등으로 구분한다.
CSV 파일 만들기
CSV 파일은 엑셀을 사용하여 간단히 만들 수 있다. 다음 순서대로 CSV 만들기
- 소스 파일에서 'csv 파일 만들기.xls' 파일을 다운로드
- 엑셀에서 다운로드한 파일을 연다.
- 메뉴 바에서 [파일] - [다른 이름으로 저장]을 선택한다.
- [다른 이름으로 저장] 대화상자에서 '파일 형식'을 'CSV(쉼표로 분리)'로 선택한 후, [저장]을 클릭한다.
- 엑셀을 종료한 후, 메모장에서 파일을 연다.
CSV 파일 다루기
- csv 파일을 다루기 위해 먼저 파이썬으로 csv 파일을 열고, 내용을 사용하는 작업을 한다. 파이썬으로 csv파일을 다루는 방법은 크게 3가지가 있다.
- 파일 객체 사용하기
- CSV 객체 사용하기
- PANDAS 객체 사용하기
파일 객체 사용해 데이터 다루기
- 파일 객체를 사용하여 데이터를 다루는 방법은 일반적인 텍스트 파일을 처리하듯 파일을 읽어 온 후, 한 줄씩 데이터를 처리하는 것이다.
- 예시 customers.csv 사용하기.
# csv 파일 객체 사용해 다루기
line_counter = 0 # 파일의 총 줄 수를 세는 변수
data_header = [] # 데이터의 필드값을 저장하는 리스트
customer_list = [] # customer의 개별 리스트를 저장하는 리스트
with open("customers.csv")as customer_data: # customer.csv 파일을 customer_data객체에 저장
while 1:
data = customer_data.readline() # 한 줄씩 data에 저장
if not data:
break # 데이터가 없을 때, 반복문 종료
if line_counter == 0: # 첫 번째 데이터는 데이터의 필드
data_header = data.split(",") # 데이터의 필드는 data_header 리스트에 저장, 데이터 저장시 ","로 분리
else:
customer_list.append(data.split(",")) # 일반 데이터는 customer_list 객체에 저장, 데이터 저장 시 ","로 분리
line_counter +=1
print("Header:", data_header) # 데이터의 필드값 출력
for i in range(0,10): #데이터 출력 (샘플 10개)
print("Data",i,":",customer_list[i])
print(len(customer_list)) # 전체 데이터 크기 출력

csv 객체를 사용해서 데이터 다루기
- 파이썬에서는 기본적으로 파일 객체가 이닌 csv 객체를 이용하여 csv 파일 형태의 데이터를 다루기 쉽다.
- 예시 자료는 서울시에서 제공하는 유동인구 정보 csv를 다운받아 사용한다.
- http://data.seoul.go.kr/dataList/OA-15766/S/1/datasetView.do
서울시 북촌 CCTV 유동인구 일간/주간/월간 수집 정보
데이터 이용하기-서울시 북촌 CCTV 유동인구 일간/주간/월간 수집 정보
data.seoul.go.kr
import csv
gye_dong_data =[] # 기본 변수명 선언
header = []
rownum = 0
with open("./서울시 북촌 CCTV 유동인구 일간_주간_월간 수집 정보.csv","r",encoding="cp949")as p_file: # 불러들일 데이터를 선언하고, 한글 처리를 위한 'cp949'
csv_data = csv.reader(p_file) # csv 객체를 이용해 csv_data 읽기, 특별히 데이터를 나누는 기준을 정하지 않음
for row in csv_data: # 읽어 온 데이터를 한 줄씩 처리
if rownum == 0 :
header = row # 첫 번째 줄을 데이터 필드로 따로 저장
location = row[0] #'기준일자'필드 데이터 추출
if location.find(u"20190930")!=-1:
gye_dong_data.append(row) # '기준일자'데이터에 계동이 있으면 gye_dong_data List에 추가
rownum +=1
with open("./계동 CCTV 유동인구 일간_주간_월갑 수집 정보.csv","w",encoding="utf-8")as s_p_file:
writer = csv.writer(s_p_file, delimiter="\t",quotechar="'",quoting=csv.QUOTE_ALL) # csv.writer를 사용해 csv파일 만들기, delimiter는 필드 구분자,
# quotechar는 필드 각 데이터를 묶는 문자, quoting은 묶는 범위
writer.writerow(header) # 제목 필드 파일에 쓰기
for row in gye_dong_data:
writer.writerow(row) # gye_dong_data의 정보를 리스트에 쓰기

