728x90
반응형
CBOW 모델 구현
# CBOW 모델 구현
import sys
sys.path.append('..')
import numpy as np
from layers import Embedding
class CBOW:
def __init__(self, vocab_size, hidden_size, window_size, corpus):
V, H = vocab_size, hidden_size
# 가중치 초기화
W_in = 0.01* np.random.rand(V, H).astype('f')
W_out = 0.01*np.random.rand(V, H).astype('f')
# 계층 생성
self.in_layers = []
for i in range(2 * window_size):
layer = Embedding(W_in) # Embedding 계층 사용
self.in_layers.append(layer)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size = 5)
# 모든 가중치와 기울기를 배열에 모은다.
layers = self.in_layers + [self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 인스턴스 변수에 단어의 분산 표현을 저장
self.word_vecs = W_in
forward()메서드와 backward()메서드
def forward(self, contexts, target):
h = 0
for i, layer in enumerate(self.in_layers):
h+=layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
loss = self.ns_loss.forward(h, target)
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return None
맥락과 타깃을 단어 ID로 나타낸 예(맥락의 윈도우 크기는 1)

CBOW 모델 학습 코드
import sys
sys.path.append('..')
import numpy as np
import config
# GPU에서 실행하려면 아래 주석을 해제하세요(CuPy 필요).
# ===============================================
# config.GPU = True
# ===============================================
import pickle
from trainer import Trainer
from optimizer import Adam
from skip_gram import SkipGram
from util import create_contexts_target, to_cpu, to_gpu
import pbt
# 하이퍼파라미터 설정
window_size = 5
hidden_size = 100
batch_size = 100
max_epoch = 10
# 데이터 읽기
corpus, word_to_id, id_to_word = pbt.load_data('train')
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
if config.GPU:
contexts, target = to_gpu(contexts), to_gpu(target)
# 모델 등 생성
model = CBOW(vocab_size, hidden_size, window_size, corpus)
# model = SkipGram(vocab_size, hidden_size, window_size, corpus)
optimizer = Adam()
trainer = Trainer(model, optimizer)
# 학습 시작
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()
# 나중에 사용할 수 있도록 필요한 데이터 저장
word_vecs = model.word_vecs
if config.GPU:
word_vecs = to_cpu(word_vecs)
params = {}
params['word_vecs'] = word_vecs.astype(np.float16)
params['word_to_id'] = word_to_id
params['id_to_word'] = id_to_word
pkl_file = 'cbow_params.pkl' # or 'skipgram_params.pkl'
with open(pkl_file, 'wb') as f:
pickle.dump(params, f, -1)
CBOW 모델 평가
import sys
sys.path.append('..')
from util import most_similar, analogy
import pickle
pkl_file = 'cbow_params.pkl'
# pkl_file = 'skipgram_params.pkl'
with open(pkl_file, 'rb') as f:
params = pickle.load(f)
word_vecs = params['word_vecs']
word_to_id = params['word_to_id']
id_to_word = params['id_to_word']
# 가장 비슷한(most similar) 단어 뽑기
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs, top=5)
# 유추(analogy) 작업
print('-'*50)
analogy('king', 'man', 'queen', word_to_id, id_to_word, word_vecs)
analogy('take', 'took', 'go', word_to_id, id_to_word, word_vecs)
analogy('car', 'cars', 'child', word_to_id, id_to_word, word_vecs)
analogy('good', 'better', 'bad', word_to_id, id_to_word, word_vecs)

출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형




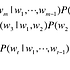
최근댓글