728x90
반응형
word2vec을 사용한 애플리케이션의 예
- word2vec으로 얻은 단어의 분산 표현은 비슷한 단어를 찾는 용도로 이용할 수 있다.
- 또, 자연어 처리 분야에서 단어의 분산 표현이 중요한 이유는 전이 학습(tramsfer learning)에 있다.
- 전이 학습은 한 분야에서 배운 지식을 다른 분야에도 적용하는 기법이다.
- 단어의 분산 표현은 단어를 고정 길이 벡터로 변환해준다는 장점도 있다.
- 문장(단어의 흐름)도 단어의 분산 표현을 사용해 고정 길이 벡터로 변환할 수 있다.
- 가장 간단한 방법은 문장의 각 단어를 분산 표현으로 변환하고 그 합을 구하는 것이다.
- bag-of-words라고 하며, 단어의 순서를 고려하지 않는 모델이다.
단어의 분산 표현을 이용한 시스템의 처리 흐름

- 자연어로 쓰여진 질문을 고정 길이 벡터로 변환할 수 있다면, 그 벡터를 다른 머신러닝 시스템의 입력으로 사용할 수 있다.
- 자연어를 벡터로 변환함으로써 일반적인 머신러닝 시스템의 틀에서 원하는 답을 출력하는 것(학습하는 것도)이 가능해진다.
단어 벡터 평가 방법
- 단어 분산 표현은 현실적으로는 특정한 애플리케이션에서 사용되는 것이 대부분이다.
- 궁극적으로 원하는 것은 정확도 높은 시스템
- 단어의 분산 표현을 만드는 시스템과 분류하는 시스템의 학습은 따로 수행할 수도 있다.
- 단어의 분산 표현의 우수성을 실제 애플리케이션과는 분리해 평가하는 것이 일반적이다.
- 자주 사용되는 평가 척도가 단어의 '유사성'이나 '유추 문제'를 활용한 평가다.
유추 문제에 의한 단어 벡터의 평가 결과
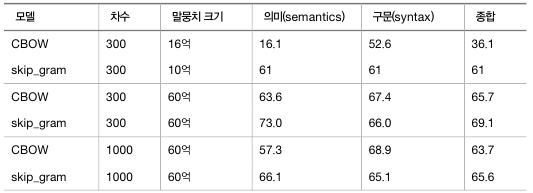
출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형





최근댓글