728x90
반응형
선형 회귀
import matplotlib.pyplot as plt # 그래프
# 사이킷런에서 당뇨병 환자 데이터 가져오기
# load_diabetes() 함수로 당뇨병 데이터 준비
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
# 입력과 타깃 데이터의 크기 확인
print(diabetes.data.shape, diabetes.target.shape) # data는 442 * 10 크기의 2차원 배열
# target은 442개의 요소를 가진 1차원 배열
# 행은 샘플(sample), 열은 샘플의 특성(feature)
# 샘플이란 당뇨병 환자에 대한 특성으로 이루어진 데이터 1세트를 의미
# 특성은 당뇨병 데이터의 여러 특징들을 의미한다.
# 당뇨병 데이터에는 환자의 혈압, 혈당, 모무게, 키 등의 특징이 있다. - 그 특징들의 수치를 모아 1세트로 만들면 1개의 샘플이 나온다.
print(diabetes.data[0:3]) # 앞부분의 입력된 데이터의 일부만 출력 - 샘플 3개 0 ~ 2
# 타깃 데이터는 10개의 요소로 구성된 샘플 1개에 대응한다.
print(diabetes.target[:3]) # diabetes.data[0:3] 대응
plt.scatter(diabetes.data[:,2],diabetes.target)
plt.xlabel("x")
plt.ylabel("y")
plt.show() # 그래프의 x축은 diabetes.data의 세 번째 특성 , y축은 diabetes.target이다.
경사 하강법
- 선형 회귀의 목표는 입력 데이터(x)와 타깃 데이터(y)를 통해 기울기(a) 와 절편(b)를 찾는 것이였다.
- 경사 하강법은 산점도 그래프를 잘 표현하는 직선의 방정식이다.
- 모델이 데이터를 잘 표현할 수 있도록 기울기(변화율)를 사용해 모델을 조금씩 조정하는 최적화 알고리즘이다.
예측값
- 입.출력 데이터(x,y)를 통해 규칙(a,b)를 발견하면 모델을 만들었다고 한다.
- 그 모델에 대해 새로운 입력값을 넣으면 어떤 출력이 나오는데, 이 값이 모델을 통해 예측한 값이다.
- 예) y = 7x + 4라는 모델에 x에 7을 넣으면 53이라는 값이 나오는데 이 값이 모델을 통해 예측한 값이다.
훈련 데이터에 잘 맞는 W와 b를 찾는 방법
- 무작위로 W와 b를 정한다. (무작위로 모델 만들기)
- x에서 샘플 하나를 선택해 y햇을 계산한다. (무작위로 모델 예측하기)
- y햇과 선택한 샘플의 진짜 y를 비교한다. (예측한 값과 진짜 정답 비교하기, 틀릴 확률 99%)
- y햇이 y와 더 가까워지도록 w, b를 조정한다 (모델 조정하기)
- 모든 샘플을 처리할 때까지 2~4 항목을 반복
w와 b가 바뀌었을 때 y햇이 어떻게 변하는지 알아내기
1. w와 b를 초기화하기
w = 1.0
b = 1.02. 훈련 데이터의 첫 번째 샘플 데이터 y햇 얻기
y_hat = x[0] * w + b
print(y_hat)

3. 타깃과 예측 데이터 비교하기
print(y[0])
4. w값 조절해 예측값 바꾸기
예측값은 1.06~로 151.0과 차이가 크다. w와 b를 좀 더 좋은 방향으로 바꾸기.
w_inc = w + 0.01
y_hat_inc = x[0] * w_inc + b
print(y_hat_inc) # w의 값을 0.1증가시킨 다음 확인 1.062~ 로 예측값이 조금 증가했다. y_)hat보다.

5. w값 조정한 후 예측값 증가 정도 확인하기
w_rate = (y_hat_inc - y_hat) / (w_inc - w)
print(w_rate) # w값 조정시 예측값의 증가 정도 확인

가중치 w 업데이트
w_new = w + w_rate
print(w_new)
변화율로 절편 업데이트
b_inc = b + 0.1
y_hat_inc = x[0] * w + b_inc
print(y_hat_inc)
b_rate = (y_hat_inc - y_hat) / (b_inc - b)
print(b_rate)
b업데이트
b_new = b + 1
print(b_new)
오차 역전파
- y햇과 y의 차이를 이용해 w와 b를 업데이트한다.
- 오차가 연이어 전파되는 모습으로 수행
가중치와 절편 적절하게 업데이트하는 방법
1. 오차와 변화율을 곱해 가중치 업데이트
err = y[0] - y_hat
w_new = w + w_rate * err
b_new = b + 1 * err
print(w_new, b_new)

2. x[1]을 사용해 오차 구하고 새로운 w와 b구하기
y_hat = x[1] * w_new + b_new
err = y[1] - y_hat
w_rate = x[1]
w_new = w_new + w_rate * err
b_new = b_new + 1 * err
print(w_new, b_new)
3. 전체 샘플 반복하기
for x_i, y_i in zip(x, y):
y_hat = x_i * w + b
err = y_i - y_hat
w_rate = x_i
w = w + w_rate * err
b = b + 1 * err
print(w, b)
*zip 함수는 여러 개의 배열에서 동시에 요소를 하나씩 꺼내준다.
4. 과정3 결과 모델 그래프 그리기
plt.scatter(x, y)
pt1 = (-0.1, -0.1 * w + b)
pt2 = (0.15, 0.15 * w + b)
plt.plot([pt1[0], pt2[0]], [pt1[1], pt2[1]])
plt.xlabel("x")
plt.ylabel("y")
plt.show()
5. 여러 에포크 반복
for i in range(1, 100): # 100번 에포크 반복
for x_i, y_i in zip(x, y):
y_hat = x_i * w + b
err = y_i - y_hat
w_rate = x_i
w = w + w_rate * err
b = b + 1 * err
print(w, b)
plt.scatter(x, y)
pt1 = (-0.1, -0.1 * w + b)
pt2 = (0.15, 0.15 * w + b)
plt.plot([pt1[0], pt2[0]], [pt1[1], pt2[1]])
plt.xlabel("x")
plt.ylabel("y")
plt.show()
데이터에 잘 맞는 머신러닝 모델
y햇 = 913.6x + 123.4
6. 모델로 예측
x = 0.18일 경우 y햇 예측
x_new = 0.18
y_pred = x_new * w + b
print(y_pred)
plt.scatter(x, y)
plt.scatter(x_new, y_pred)
plt.xlabel("x")
plt.ylabel("y")
plt.show()
주황색 점이 x가 0.18일 경우 예측한 y햇
728x90
반응형





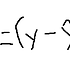

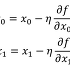
최근댓글