728x90
반응형
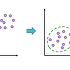
k-평균 군집(k-means clustering)
k-평균 군집의 절차(알고리즘)
- 군집의 수만큼(k개) 초기값을 지정
- 각 개체를 가까운 초기값에 할당하여 군집을 형성
- 각 군집의 평균을 재계산하여 초기값을 갱신
- 갱신된 값에 대해 위의 할당 과정을 반복하여 k개의 최종 군집을 형성
- k-평균 군집에서 군집의 수(k)는 미리 정해주어야 함
- k-개의 초기 중심값은 임의로 선택, 자료값 중 무작위 선택
- 초기 중심점들은 서로 멀리 떨어져 있는 것이 바람직
- 초기값에 따라 군집 결과가 크게 달라질 수 있음
- k-평균 군집은 군집의 매 단계마다 군집 중심으로부터 오차 제곱합을 최소화하는 방향으로 군집을 형성해나 가는(부분 최적화 수행하는) “탐욕적 알고리즘”으로 간주될 수 있으며, 안정된 군집은 보장하나 전체적으로 최적이라는 것은 보장하지 못함

k-평균 군집의 장점
- 알고리즘이 단순
- 빠르게 수행
- 계층적 군집보다 많은 양의 자료를 다룰 수 있음
- 모든 변수가 연속적이어야 함
k-평균 군집의 단점
- 잡음이나 이상값에 영향을 많이 받으며(군집 중심 계산 과정),
- 볼록한 형태가 아닌(non-convex) 군집(U-형태 군집)이 존재할 경우에는 성능이 떨어짐
이상값 자료에 민감한 k-평균 군집의 단점을 보완하는 방법
→ 매 단계마다 평균 대신 중앙값을 사용하는 k-중앙값 군집 사용, 탐색적 자료 분석을 통해 이상값을 미리 제
거하는 방법
예제)
# rattle 패키지에서 제공하는 178개의 이탈리안 와인에 대해 13가지 화학적 성분을 측정한 자료
install.packages("rattle") # rattle 패키지 install
library(rattle)
library(cluster)
data(wine)
head(wine) # type data포함
d <- scale(wine[-1]) # scale함수는 표준화를 해준다.
set.seed(1234) # set.seed를 이용해서 값을 고정시킨다. 이유는 초기값에 따라서 변동이 크기 때문에
fit.km <- kmeans(d,3,nstart=25) # 최적의 시작을 알기위해서 nstart = 25 25번중 최고의 결과만 보여준다.
fit.km
fit.km$center # 중심점에 대한 정보 확인
plot(d,col=fit.km$cluster) # 산점도
points(fit.km$center,col=1:3,pch=8,cex=1.5) # 산점도
clusplot(d,fit.km$cluster, color = TRUE, shade =TRUE, labels =2, lines = 1) # 군집 상세하게 보기
ct.km <- table(wine$Type,fit.km$cluster) # table을 이용하면 얼마나 정확한 군집을 다루는지 확인할 수 있다.
ct.km





출처 : 2020 전면 개정판 ADsP 데이터 분석 준전문가 DATAEDU
728x90
반응형







최근댓글