728x90
반응형
대상 데이터 표준화 후 군집화
- 데이터와 데이터의 거리를 계산할 때 발생하는 문제의 예 [그림1]
- A와 B 거리의 계산 값 [그림2]
- 한계점 : 거리 계산에 있어서 키의 값은 많이 반영되는데(100), 시력은 거리 계산에 있어서 거의 영향을 미치지 못한다.(0.09)
- 즉, 자료의 범위가 큰 변수가 거리 계산에 있어서 더 많은 영향을 미칠수밖에 없다는 의미다.
- 분석자들은 모든 변수가 거리 계산에 동등한 영향을 갖도록 하기 위해서 모든 변수의 자료 범위를 0~1 사이로 표준화한 후에 거리 계산
- 변수 A의 값들을 0~1 사이로 표준화하는 공식 - (x-min(A)) / (max(A) - min(A))


R 대상 데이터 표준화 후 군집화
# 대상 데이터 표준화 후 군집화
std <- function(X){
return((X-min(X))/ (max(X)-min(X)))
}
mydata <- apply(iris[,1:4],2,std)
fit <- kmeans(x=mydata, centers=3)
fit
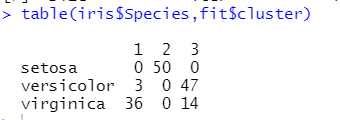
table(iris$Species,fit$cluster)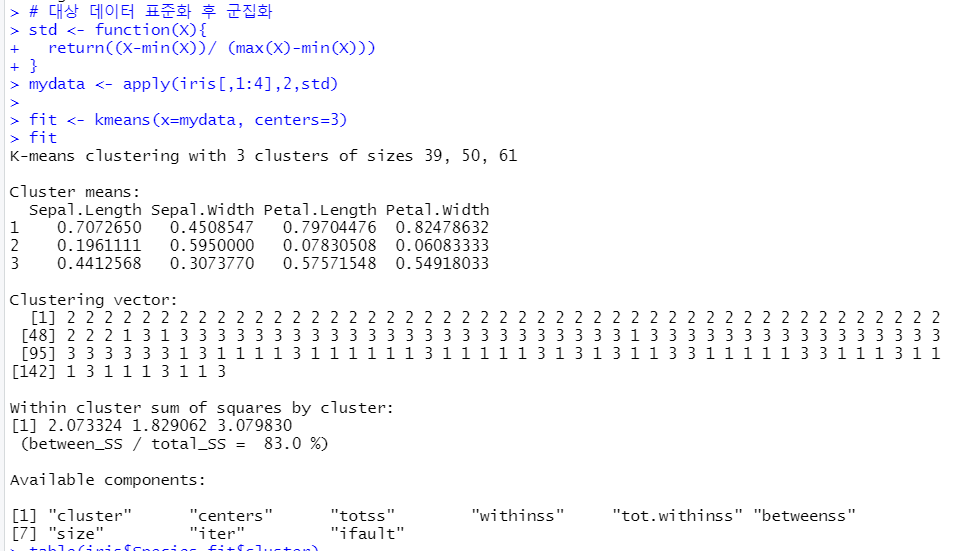
출처 : 모두를 위한 R 데이터 분석 입문 한빛아카데미
728x90
반응형







최근댓글