k - 평균 군집화의 과정
1단계 : 대상 데이터셋을 준비한다. 이때 산점도 상의 점 하나가 관측값 하나를 의미한다.
2단계 : 산점도 상에 임의의 점 2개(*와 +)를 만든다. 이 2개의 점은 나중에 군집이 완성되었을 때 각 군집의 중심점이 된다. 따라서 군집의 개수만큼 임의의 점을 생성한다.
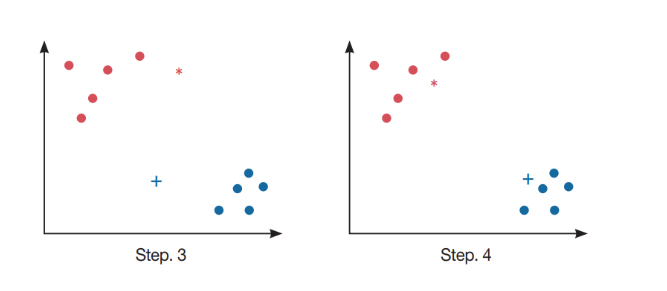
3단계 : 산점도 상의 점들 하나하나와 임의의 점 2개와의 거리를 계산하여 두 점 중 가까운 쪽으로 군집을 형성한다. 그 결과 그래프의 왼쪽 위의 점들은(*)군집으로, 오른쪽 아래의 점들은(+)군집으로 묶였다.
4단계 : 두 개의 군집에서 중심점을 다시 계산(*와 +도 포함해 계산) (*)의 위치와 (+)의 위치를 새로 계산한 중심점의 위치로 이동한다.
5단계 : 4단계의 과정을 반복한다.
6단계 : (*)와 (+)의 위치가 더 이상 변동되지 않으면 군집의 중심점에 도달했으므로 반복을 중단한다.
7단계 : 마지막으로 (*)와 가까운 점들은 (*)군집으로 (+)와 가까운 점들은 (+)군집으로 표시한다. 군집화를 종료.


* 즉, k - 평균 군집화의 방법을 정리하면 먼저 군집의 중심점을 찾고, 다른 점들은 거리가 가장 가까운 중심점의 군집에 속하는 것으로 결정한다.
유클리디안 거리를 이용하면 n차원 상의 점 p, q의 거리는 다음과 같이 계산된다.
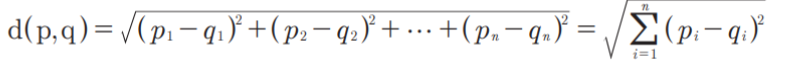
R에서 k-평균 군집화 예
# k-평균 군집화
mydata <- iris[,1:4] # 데이터 준비
fit <- kmeans(x=mydata,centers=3) # 군집화 개수 centers 3
fit
fit$cluster # 각 데이터에 대한 군집 번호
fit$centers # 각 군집의 중심점 좌표
# 차원 축소 후 군집 시각화
library(cluster)
clusplot(mydata, fit$cluster, color = TRUE, shade=TRUE, labels=2, lines=0)
# color, shade 는 색과 명암? false는 안하겠다는 의미
subset(mydata,fit$cluster==2)# 데이터에서 두번째 군집의 데이터만 출력한다.



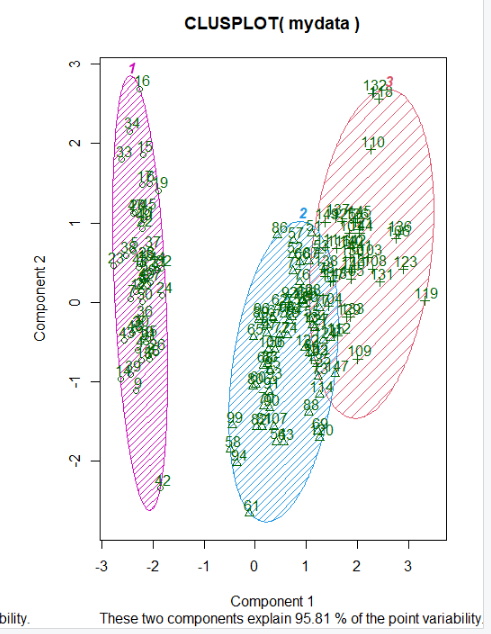
출처 : 모두를 위한 R 데이터 분석 입문 한빛아카데미






최근댓글