728x90
반응형
Encoder 클래스
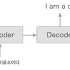
- Encoder 클래스는 아래 [그림1]처럼 문자열을 입력받아 벡터 h로 변환한다.
Encoder의 입출력

- RNN을 이용해 Encoder를 구성 - LSTM 계층 이용
Encoder의 계층 구성

- Encoder 클래스는 Embedding 계층과 LSTM 계층으로 구성
- Embedding 계층에서는 문자(문자 ID)를 문자 벡터로 변환한다.
- 문자 벡터가 LSTM 계층으로 입력된다.
- Encoder에서는 LSTM의 은닉 상태만을 Decoder에 전달한다.
- LSTM의 셀도 Decoder에 전달할 수 있찌만, LSTM의 셀을 다른 계층에 전달하는 일은 일반적으로 흔하지 않다.
- LSTM의 셀은 자신만 사용한다는 전제로 설계되었기 때문이다.
Decoder 클래스
- Encoder 클래스가 출력한 h를 받아 목적으로 하는 다른 문자열을 출력합니다.
Encoder와 Decoder

Decoder의 계층 구성(학습 시)

- 정답 데이터는 "_62", 입력 데이터 = ['_','6','2','']로 주고, 이에 대응하는 출력은 ['6','2','','']이 되도록 학습시킨다.
Decoder의 문자열 생성 순서 : argmax 노드는 Affine 계층의 출력 중 값이 가장 큰 원소의 인덱스(문자ID)를 반환한다.

- argmax노드는 최댓값을 가진 원소의 인덱스(문자ID)를 선택하는 노드
- Softmax 계층은 입력된 벡터를 정규화한다.
- 정규화 과정에서 벡터의 각 원소의 값이 달라진다.
- 대소 관계는 바뀌지 않는다.
- 따라서 위의 그림은 Softmax 계층을 생략할 수 있다.
Decoder 클래스의 구성

- Decoder 클래스는 Time Embedding, Time LSTM, Time Affine 3가지 계층으로 구성
Decoder 클래스
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, h):
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh- Decoder 클래스는 학습 시와 문장 생성 시의 동작이 다르다.
- 앞의 forward() 메서드는 학습할 때 사용된다고 가정
- 문장 생성을 담당하는 generate() 메서드 구현
def generate(self, h, start_id, sample_size):
sampled = []
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1, 1))
out = self.embed.forward(x)
out = self.lstm.forward(out)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(int(sample_id))
return sampled- generate() 메서드는 인수 3개를 받는다. - Encoder로부터 받는 은닉 상태 h, 최초로 주어지는 문자 ID인 start_id, 생성하는 문자 수인 sample_size
- 여기서 문자를 1개씩 주고, Affine 계층이 출력하는 점수가 가장 큰 문자 ID를 선택하는 작업을 반복한다.
Seq2seq 클래스
- Encoder 클래스와 Decoder 클래스를 연결하고 Time Softmax with Loss 계층을 이용해 손실을 계산
class Seq2seq(BaseModel):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = Decoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
def forward(self, xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs, h)
loss = self.softmax.forward(score, decoder_ts)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(dout)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled
seq2seq 평가
- 학습 데이터에서 미니배치를 선택
- 미니배치로부터 기울기를 계산
- 기울기를 사용해 매개변수를 갱신
출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형






최근댓글