728x90
반응형
seq2seq의 원리
- 2개의 RNN을 이용
- Encoder-Decoder 모델
- 2개의 모듈, Encoder와 Decoder가 등장한다.
- Encoder는 입력 데이터를 인코딩(부호화)한다.
- Decoder는 인코딩된 데이터를 디코딩(복호화)한다.
Encoder와 Decoder가 번역을 수행하는 예

- Encoder와 Decoder가 협력하여 시계열 데이터를 다른 시계열 데이터로 변환한다.
- Encoder와 Decoder로는 RNN를 사용할 수 있다.
Encoder를 구성하는 계층

- Encoder는 RNN을 이용해 시계열 데이터를 h라는 은닉 상태 벡터로 변환한다.
- RNN으로써의 LSTM을 이용했지만, '단순한 RNN'이나 GRU 등도 물론 이용 가능하다.
- Encoder가 출력하는 벡터 h는 LSTM 계층의 마지막 은닉 상태다.
- 은닉 상태 h에 입력 문장(출발어)을 번역하는 데 필요한 정보가 인코딩된다.
- LSTM의 은닉 상태 벡터 h는 고정 길이 벡터다.
- 인코딩한다는 것은 임의 길이의 문장을 고정 길이 벡터로 변환하는 작업이다.
Encoder는 문장을 고정 길이 벡터로 인코딩한다.

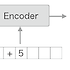
Decoder를 구성하는 계층

- LSTM 계층이 벡터 h를 입력받는 점이 다르고 나머지는 같다.
- <eos>는 구분 기호(특수 문자)다. '구분자'이며, 문장 생성의 시작을 알리는 신호로 이용된다.
seq2seq의 전체 계층 구성

- LSTM의 은닉 상태가 Encoder와 Decoder를 이어주는 '가교'가 된다.
- 순전파 때는 Encoder에서 인코딩 된 정보가 LSTM 계층의 은닉 상태를 통해 Decoder에 전해진다.
사계열 데이터 변환용 장난감 문제
- 57+5 와 같은 문자열을 seq2seq에 건네면 62라는 정답을 내놓도록 학습시키기
- 머신러닝을 평가하고자 만든 간단한 문제를 '장난감 문제(tory problem)'이라고 한다.
seq2seq에 덧셈 예제들을 학습시킨다.

- seq2seq는 덧셈 논리에 대해 아무것도 모르니 학습을 시켜야 한다.
- word2vec이나 언어 모델에서는 문장을 '단어' 단위로 분할해왔다.
- 하지만 모든 문장에서 단어 단위로 분할해야 하는 것은 아니다.
- 이번에는 '문자' 단위로 분할한다.
- 예) ['5', '7', '+', '5']라는 리스트로 처리
가변 길이 시계열 데이터
- '미니배치 처리'를 하려면 무언가 추가해야 한다.
- '미니배치 처리'로 학습할 때는 다수의 샘플을 한꺼번에 처리하며 한 미니배치에 속한 샘플들의 데이터 형상이 모두 똑같아야 한다.
- 시계열 데이터를 미니배치로 학습하기 위한 가장 단순한 방법은 패딩(padding)이다.
미니배치 학습을 위해 '공백 문자'로 패딩을 수행하여 입력, 출력 데이터의 크기를 통일한다.

- 임의로 0~999 사이의 숫자 2개만 더하는 것으로 설정
- '+'까지 포함하면 최대 문자 수는 7이 된다.
- 출력 데이터는 최대 4문자이고 출력 데이터는 구분하기 위해 앞에 (_)를 붙인다.
- 패딩을 적용해 데이터를 통일시키면 가변 길이의 시계열 데이터도 처리할 수 있다.
- 원래는 존재하지 않는 패딩용 문자(공백)까지 처리해야 하므로 정확성이 중요하다면 seq2seq에 패딩 전용 처리를 추가해야 한다.
덧셈 데이터셋
# show_addition_dataset
import sys
sys.path.append('..')
import sequence
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt', seed=1984)
char_to_id, id_to_char = sequence.get_vocab()
print(x_train.shape, t_train.shape)
print(x_test.shape, t_test.shape)
print(x_train[0])
print(t_train[0])
print(''.join([id_to_char[c] for c in x_train[0]]))
print(''.join([id_to_char[c] for c in t_train[0]]))

출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형






최근댓글