728x90
반응형
언어 모델을 사용한 문장 생성
- 언어 모델은 다양한 애플리케이션에 활용할 수 있다.
- 대표적인 예)
- 기계 번역
- 음성 인식
- 문장 생성등
RNN을 사용한 문장 생성의 순서
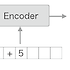
- LSTM계층을 이용해 언어모델을 구현 - 신경망 구성은 [그림1]
- 시계열 데이터를 (T개분 만큼)모아 처리하는 Time LSTM과 Time Affine 계층 등을 만듬
언어 모델 : 오른쪽은 시계열 데이터를 한꺼번에 처리하는 Time 계층을 사용 왼쪽은 같은 구성을 펼친 모습

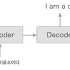
언어 모델은 다음에 출현할 단어의 확률분포를 출력한다.

- 언어 모델은 지금까지 주어진 단어들에서 다음에 출현하는 단어의 확률분포를 출력한다.
- 다음 단어를 새로 생성하려면
- 확률이 가장 높은 단어를 선택하는 방법
- 확률이 가장 높은 단어를 선택,결과가
- '확률적'으로 선택하는 방법도 생각할 수 있음
- 확률이 높은 단어는 선택되기 쉽고, 확률이 낮은 선택되기 어려움
- 선택되는 단어(샘플링 단어)가 매번 다를 수 있다.
- 확률이 가장 높은 단어를 선택하는 방법
문장 생성 구현
import sys
sys.path.append('..')
import import_ipynb
from functions import softmax
from CH06 import Rnnlm
from CH06 import BetterRnnlm
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
x = np.array(x).reshape(1, 1)
score = self.predict(x)
p = softmax(score, flatten())
sampled = np.random.choice(len(p), size= 1, p = p)
if(skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_iids.append(int(x))
return word_ids
# 문자 생성을 수행하는 generate(start_id, skip_ids, sample_size) start_id = 단어 ID, sample_size = 샘플링하는 단어의 수- generate) 메서드는 가장 먼저 model.predict(x)를 호출해 각 단어의 점수 출력(정규화 전의 점수)
- p = softmax(score) 코드에서는 점수들을 소프트맥스 함수를 이용해 정규화한다.
- 목표로 하는 확률분포 p 얻음 - 그 후 확률분포 p로 단어 샘플링
RnnlmGen 클래스 사용해 문장 생성
import sys
sys.path.append('..')
import pbt
corpus, word_to_id, id_to_word = pbt.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen()
model.load_params('../ch06/Rnnlm.pkl')
# start 문자와 skip 문자 설정
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]
# 문장 생성
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print(txt)
출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형






최근댓글