728x90
반응형
LSTM 계층 다층화
- RNNLM으로 정확한 모델을 만들고자 한다면 많은 경우 LSTM 계층을 깊게 쌓아(계층을 여러겹 쌓아) 효과를 볼 수 있다.
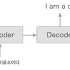
LSTM 계층을 2층으로 쌓은 RNNLM

- 첫 번째 LSTM 계층의 은닉 상태가 두 번째 LSTM 계층에 입력된다.
- LSTM 계층을 몇 층이라도 쌓을 수 있으며, 덕분에 더 복잡한 패턴을 학습할 수 있게 된다.
드롭아웃에 의한 과적합 억제
- 층을 깊게 쌓음으로써 표현력이 풍부한 모델을 만들 수 있지만, 이런 모델은 종종 과적합(overfitting,과대적합)을 일으킨다.
- 게다가 RNN은 일반적인 피드포워드 신경망보다 쉽게 과적합을 일으킨다는 소식이다.
- 과적합 억제하는 전통적인 방법
- '훈련 데이터의 양 늘리기'와 '모델의 복잡도 줄이기'
- 모델의 복잡도에 페널티를 주는 정규화(normalization)도 효과적이다.
- L2 정규화는 가중치가 너무 커지면 페널티를 부과한다.
- 드롭아웃(dropout)처럼 훈련 시 계층 내의 뉴런 몇 개(예컨대 50% 등)를 무작위로 무시하고 핛브하는 방법도 일종의 정규화
드롭아웃의 개념도(왼쪽이 일반적 신경망, 오른쪽이 드롭아웃을 적용한 신경망)

- 드롭아웃은 무작위로 뉴런을 선택해 선택한 뉴런을 무시한다.
- 무시한다는 의미는 그 앞 계층으로부터의 신호 전달을 막는다는 뜻이다.
- '무작위한 무시'가 제약이 되어 일반화 성능을 개선한다.
피드포워드 신경망에 드롭아웃 계층을 적용하는 예

RNN 모델에서의 드롭아웃 계층

- 시간축 방향으로의 드롭아웃은 시간의 흐름에 따라 정보가 사라질 수 있다.
- [그림4]처럼 드롭아웃 계층을 깊이 방향(상하 방향)으로 삽입하는 방법이 좋다.
- 시간 방향(좌우 방향)으로 아무리 진행해도 정보를 잃지 않는다.
- 드롭아웃이 시간축과는 독립적으로 깊이 방향(상하 방향)에만 영향을 주기 때문이다.
하지만 최근 연구에서 RNN의 시간 방향 정규화를 목표로 하는 방법이 다양하게 제안
이것이 변형 드롭아웃(Variational Dropout)
변형 드롭아웃의 예
- 색이 같은 드롭아웃끼리는 같은 마스크를 이용
- 같은 계층에 적용되는 드롭아웃끼리는 공통의 마스크를 이용함으로 시간 방향 드롭아웃도 효과적으로 작동가능

가중치 공유(weight tying)
- 언어 모델을 개선하는 아주 간단한 트릭
- 가중치를 공유하는 효과를 준다.
언어 모델에서의 가중치 공유 예
- Embedding 계층과 Softmax 앞단의 Affinen 계층이 가중치를 공유한다.

- 가중치를 공유함으로 학습하는 매개변수 수가 크게 줄어드는 동시에 정확도도 향상되는 일석이조의 기술
개선된 RNNLM 구현
BetterRnnlm 클래스의 신경망 구성

개선점
- LSTM 계층의 다층화(여기선 2층)
- 드롭아웃 사용(깊이 방향으로만 적용)
- 가중치 적용(Embedding 계층과 Affine 계층에서 가중치 공유)
BetterRnnlm 클래스
# BetterRnnlm 클래스
import sys
sys.path.append('..')
from time_layers import *
from np import *
from base_model import BaseModel
class BetterRnnlm(BaseModel):
def __init__(self, vocab_size = 10000, wordvec_size=650, hidden_size=650, dropout_ratio=0.5):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D)/ 100).astype('f')
lstm_Wx1 = (rn(D, 4 * H)/np.sqrt(D)).astype('f')
lstm_Wh1 = (rn(H, 4 * H)/np.sqrt(H)).astype('f')
lstm_b1 = np.zeros(4 * H).astype('f')
lstm_Wx2 = (rn(H, 4 * H)/np.sqrt(H)).astype('f')
lstm_Wh2 = (rn(H, 4 * H)/np.sqrt(H)).astype('f')
lstm_b2 = np.zeros(4*H).astype('f')
affine_b = np.zeros(V).astype('f')
# 세 가지 개선
self.layers = [
TimeEmbeding(embed_W),
TimeDropout(dropout_ratio).
TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True),
TimeDropout(dropout_ratio)
TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True),
TimeDropout(dropout_ratio),
TimeAffine(embed_W.T, affine_b) # 가중치 공유
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layers = [self.layers[2],self.layers[4]]
self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs, train_flag = False):
for layer in self.drop_layers:
layer.train_flg = train_flg
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts, train_flg=True):
score = self.predict(xs, train_flg)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
for layer in self.lstm_layers:
layer.reset_state()학습용 코드
import sys
sys.path.append('..')
import config
from optimizer import SGD
from trainer import RnnlmTrainer
from util import eval_perplexity
import pbt
config.GPU = True
# 하이퍼파라미터 설정
batch_size = 20
wordvec_size = 650
hidden_size = 650
time_size = 35
lr = 20.0
max_epoch = 40
max_grad = 0.25
dropout = 0.5
# 학습 데이터 읽기
corpus, word_to_id, id_to_word = pbt.load_data('train')
corpus_val, _, _ = pbt.load_data('val')
corpus_test, _, _ = pbt.load_data('test')
if config.GPU:
corpus = to_gpu(corpus)
corpus_val = to_gpu(corpus_val)
corpus_test = to_gpu(corpus_test)
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
model = BetterRnnlm(vocab_size, wordvec_size, hidden_size, dropout)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
best_ppl = float('inf')
for epoch in range(max_epoch):
trainer.fit(xs, ts, max_epoch=1, batch_size=batch_size,
time_size=time_size, max_grad=max_grad)
model.reset_state()
ppl = eval_perplexity(model, corpus_val)
print('검증 퍼플렉서티: ', ppl)
if best_ppl > ppl:
best_ppl = ppl
model.save_params()
else:
lr /= 4.0
optimizer.lr = lr
model.reset_state()
print('-' * 50)
# 테스트 데이터로 평가
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('테스트 퍼플렉서티: ', ppl_test)
첨단 연구로
- 첨단 연구에서의 PTB 데이터셋 테스트 데이터
PTB 데이터셋에 대한 각 모델의 퍼블렉서티 결과

출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형






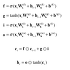
최근댓글