728x90
반응형
언어 모델 신경망 구성(왼쪽 Time RNN, 오른쪽 Time LSTM)

LSTM 계층을 사용하는 Rnnlm 클래스
# LSTM 계층을 사용하는 Rnnlm 클래스
import sys
sys.path.append('..')
from time_layers import *
import pickle
class Rnnlm:
def __init__(self, vocab_size = 10000, wordvec_size = 100, hidden_size=100):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 가중치 초기화
embed_W = (rn(V, D)/ 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) /np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# 계층 생성
self.layers = [
TimeEmbedding(embed_W),
TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layer = self.layers[1]
# 모든 가중치와 기울기를 리스트에 모은다.
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts):
score = self.predict(xs)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout = 1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.lstm_layer.reset_state()
def save_arams(self, file_name = 'Rnnlm.pkl'):
with open(file_name, 'wb') as f:
pickle.dump(self.params, f)
def load_params(self, file_name = 'Rnnlm.pkl'):
with open(file_name, 'rb') as f:
self.params = pickle.load(f)
PTB 데이터셋 학습
# PTB 데이터셋 학습
import sys
sys.path.append('..')
from optimizer import SGD
from trainer import RnnlmTrainer
from util import eval_perplexity
import pbt
# 하이퍼파라미터 설정
batch_size = 20
wordvec_size = 100
hidden_size = 100 # RNN의 은닉 상태 벡터의 원소 수
time_size = 35 # RNN을 펼치는 크기
lr = 20.0
max_epoch = 4
max_grad = 0.25
# 학습 데이터 읽기
corpus, word_to_id, id_to_word = pbt.load_data('train')
corpus_test, _, _ = pbt.load_data('test')
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
# 모델 생성
model = Rnnlm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
# 기울기 클리핑을 적용해 학습
trainer.fit(xs, ts, max_epoch, batch_size, time_size, max_grad, eval_interval=20)
trainer.plot(ylim=(0,500))
# 20번재 반복마다 퍼블렉서티를 평가
# 데이터가 크기 때문에 모든 에폭에서 평가하지 않고, 20번 반복될 때마다 평가
# 테스트 데이터로 평가
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('테스트 퍼블렉서티 : ', ppl_test)
# 테스트 데이터를 이용해 퍼블렉서티 평가
# 모델 상태 LSTM의 은닉 상태와 기억 셀를 재설정해 평가를 수행
# 매개변수 저장
model.save_params()


기울기
# 기울기 구하기
model.forward(...)
model.backward(...)
params, grads = model.params, model.grads
# 기울기 클리핑
if max_grad is not None:
clip_grads(grads, max_grad)
# 매개변수 갱신
optimizer.update(params, grads)
- 4에폭으로 최종적으로 퍼블렉서티 100정도
- 테스트 136은 그리 좋은 결과는 아니다.
- 2017년 기준 최첨단 연구에서는 60을 밑돌고 있다. (개선 여지가 많다는 의미)
출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형






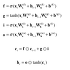
최근댓글