728x90
반응형
최근에는 단순한 RNN 대신 LSTM이나 GRU라는 계층이 주로 쓰인다.
LSTM이나 GRU에는 '게이트(gate)'라는 구조가 더해져 있다.
게이트 덕분에 시계열 데이터의 장기 의존 관계를 학습할 수 있다.
RNN의 문제점
- RNN은 시계열 데이터의 장기 의존 관계를 학습하기 어렵다.
- BPTT에서 기울기 소실 혹은 기울기 폭발이 일어나기 때문
RNN 복습
- RNN계층은 순환 경로를 가지고 있다.
RNN 계층 : 순환 펼치기 전과 후

- RNN계층은 시계열 데이터 xi를 입력하면 hi를 출력한다.
- hi는 RNN계층의 은닉 상태라고 하며, 과거 정보를 저장한다.
- 이전 시각의 은닉 상태를 이용한다는 점이 특징이다. - 과거 정보를 계승할 수 있게 된다.
RNN 계층의 계산 그래프(MatMul 노드는 행렬 곱을 나타낸다.)

기울기 소실 또는 기울기 폭발
RNNLM 학습의 관점에서
- "Tom"이란 단어가 주어졌을 때, RNNLM에서 기울기가 어떻게 전파되는지 보기, BPTT로 수행
- 정답 레이블이 "Tom"이라고 주어진 시점으로부터 과거 방향으로 기울기를 전달하게 된다.
정답 레이블이 "Tom"임을 학습할 때의 기울기 흐름

- 정답 레이블이 "Tom"임을 학습할 때 중요한 것이 바로 RNN 계층의 존재
- RNN 계층이 과거 방향으로 '의미 있는 기울기'를 전달함으로써 시간 방향의 의존 관계를 학습할 수 있다.
- 기울기는 학습해야 할 의미가 있는 정보가 들어 있고, 그것을 과거로 전달함으로 장기 의존 관계를 학습한다.
- 하지만 기울기가 중간에 사그라들면 가중치 매개변수는 전혀 갱신되지 않게 된다. - 장기 의존 관계를 학습할 수 없게 된다.
기울기 소실과 기울기 폭발의 원인
RNN 계층에서 시간 방향으로의 기울기 전파

- 길이가 T인 시계열 데이터 가정
- T번째 정답 레이블이 "Tom"인 경우, 시간 방향 기울기에 주목하면 역전파로 전해지는 기울기는 차례로 'tanh', '+', 'MatMul(행렬 곱)' 연산을 통과한다는 것을 알 수 있다.
- '+' 역전파는 상류에서 전해지는 기울기를 하류로 흘려보낼 뿐이다.
y = tanh(x)의 그래프(점선은 미분)

- 점선은 y = tanh(x)의 미분, 값은 1.0 이하이고, x가 0으로부터 멀어질수록 작아진다.
- 역전파에서는 기울기가 tanh 노드를 지날 때마다 값은 계속 작아진다는 뜻이다.
- tanh 함수를 T번 통과하면 기울기도 T번 반복해서 작아지게 된다.
RNN 계층의 행렬 곱에만 주목했을 때의 역전파의 기울기(tanh 무시)

- 상류로부터 dh라는 기울기가 흘러온다고 가정
- MatMul 노드에서 dhWh^T라는 행렬 곱으로 기울기를 계산
기울기 크기 변화 관찰
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager
N = 2 # 미니배치 크기
H = 3 # 은닉 상태 벡터의 차원 수
T = 20 # 시계열 데이터의 길이
dh = np.ones((N,H))
np.random.seed(3) # 재현할 수 있도록 난수의 시드 고정
Wh = np.random.rand(H, H)
norm_list = []
for t in range(T):
dh = np.matmul(dh, Wh.T)
norm = np.sqrt(np.sum(dh**2)) / N
norm_list.append(norm)
print(norm_list)
plt.plot(np.arange(len(norm_list)), norm_list)
plt.xticks([0, 4, 9, 14, 19], [1, 5, 10, 15, 20])
plt.rc('font', family='Malgun Gothic') # 폰트
plt.xlabel('시간 크기(time step)')
plt.ylabel('노름(norm)')
plt.show()
기울기 dh는 시간 크기에 비례해 지수적으로 증가

- 기울기의 크기는 시간에 비례해 지수적으로 증가한다.
- 이것이 기울기 폭발(exploding gradients)다.
- 기울기 폭발이 일어나면 오버플로를 일으켜 NaN(Not a Number)같은 같을 발생시킨다.
Wh의 초깃값 변경 후 두 번째 실험
Wh = np.random.rand(H, H) * 0.5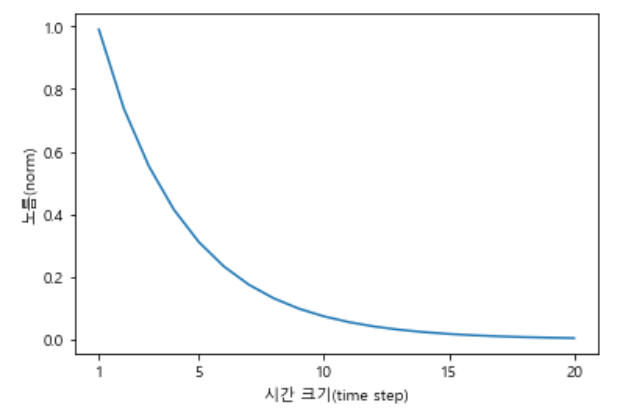
- 기울기가 지수적으로 감소한다. - 기울기 소실(vanishing gradients)
- 기울기 소실이 일어나면 기울기가 매우 빠르게 작아진다.
- 기울기가 일정 수준 이하로 작아지면 가중치 매개변수가 더 이상 갱신되지 않으므로, 장기 의존 관계를 학습할 수 없게 된다.
기울기 폭발 대책
- 전통적인 기법의 기울기 클리핑(gradients clipping)
기울기 클리핑

클리핑 구현
# 기울기 클리핑
dW1 = np.random.rand(3,3) * 10
dW2 = np.random.rand(3,3) * 10
grads = [dW1,dW2]
max_norm = 5.0
def clip_grads(grads, max_norm):
total_norm = 0
for grad in grads:
total_norm += np.sum(grad ** 2)
total_norm = np.sqrt(total_norm)
rate = max_norm / (total_norm + 1e-6)
if rate < 1:
for grad in grads:
grad *= rate
출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형




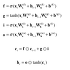
최근댓글