728x90
반응형
RNN 구현
- Truncated BPTT 방식의 학습을 따른다면, 가로 크기가 일정한 일련의 신경망을 만들면 된다.
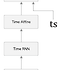
RNN에서 다루는 신경망(가로 길이는 고정)

- 길이가 T인 시계열 데이터를 받는다.(T는 임의의 값)
- 각 시각의 은닉 상태를 T개 출력한다.
Time RNN 계층
- 순환 구조를 펼친 후의 계층들을 하나의 계층으로 간주한다.

- 상하 방향의 입력과 출력을 각각 하나로 묶으면 옆으로 늘어선 일련의 계층을 하나의 계층으로 간주할 수 있다.
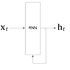
- (x0,x1,...,xt-1)을 묶은 xs를 입력하면 (h0,h1,...,ht-1)를 출력하는 단일 계층으로 볼 수 있다.
- Time RNN 계층 내에서 한 단계의 작업을 수행하는 계층을 'RNN 계층'이라 하고, T개 단계분의 작업을 한꺼번에 처리하는 계층을 'Time RNN 계층'이라고 한다.
RNN 계층 구현
RNN의 순전파 수식

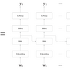
행렬 형상 확인
- 미니배치 크기 N
- 입력 벡터 차원 수 D
- 은닉 상태 벡터의 차원 수가 H
형상 확인 : 행렬 곱에서는 대응하는 차원의 원소 수를 일치시킨다.(편향 생략)

RNN 클래스 초기화와 순전파 메서드
# RNN 구현
class RNN:
def __init__(self, Wx, Wh, b): # 가중치2개 편향 1개
self.params = [Wx,Wh, b]
self.grads = [np.zeros_like(Wx),np.zeros_like(Wh),np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.matmul(h_prev, Wh) + np.matmul(x, Wx) + b
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next)
return h_nextRNN 계층의 계산 그래프(MatMul 노드는 행렬의 곱셈을 나타냄)

- MatMul과 +, tanh이라는 3개의 연산으로 구성
- 편향 b의 덧셈에서는 브로드캐스트가 일어나기 떄문에 정확하게는 Repeat 노드를 이용한다.
RNN 계층의 계산 그래프(역전파 포함)

RNN 계층의 backward()메서드
def backward(self, dh_next):
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache
dt = dh_next * (1-h_next ** 2)
db = np.sum(dt, axis = 0)
dWh = np.matmul(h_prev.T, dt)
dh_prev = np.matmul(dt, Wh.T)
dWx = np.matmul(x.T, dt)
dx = np.matmul(dt, Wx.T)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prev
Time RNN 계층 구현
- T개의 RNN 계층으로 구성된다. (T는 임의의 수로 설정가능)
Time RNN 계층과 RNN 계층

- Time RNN 계층은 RNN을 T개 연결한 신경망
- RNN 계층의 은닉 상태 Time RNN 계층에서 관리
TimeRNN 초기화 메서드와 다른 메서드2
# TimeRNN
class TimeRNN:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx,Wh, b]
self.grads = [np.zeros_like(Wx), np/zeros_like(Wh),np.zeros_like(b)]
self.layers = None
self.h, self.dh = None, None
self.stateful = stateful
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = None
TimeRNN 순전파 구현
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
D, H = Wx.shape
self.layers = []
hs = np.empty((N, T, H), dtype = 'f')
if not self.stateful or self.h is None:
self.h = np.zeros((N,H), dtype='f')
for t in range(T):
layer = RNN(*self.params)
self.h = layer.forward(xs[:,t,:],self.h)
hs[:, t, :] = self.h
self.laers.append(layer)
return hs- xs는 T개 분량의 시계열 데이터를 하나로 모은 것
- 미니배치 크기 N, 입력 벡터의 차원 수를 D, xs의 형상은(N, T, D)가 된다.
Time RNN 계층의 역전파

- 상류(출력 쪽 층)에서 전해지는 기울기를 dhs
- 하류로 내보내는 기울기를 dxs로 쓴다.
t번째 RNN 계층의 역전파

- t번째 RNN 계층에서는 위로부터의 기울기 dht와 '한 시각 뒤(미래) 계층'을부터의 기울기 dhnext가 전해진다.
Time RNN 계층의 역전파
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D, H = Wx.shape
dxs = np.empty((N, T, D), dtype='f')
dh = 0
grads = [0,0,0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh = layer.backward(dhs[:, t, :] + dh) # 합산된 기울기
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형




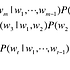
최근댓글