728x90
반응형
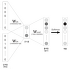
CBOW 모델

어휘가 100만 개, 은닉층 뉴런이 100개인 CBOW모델

두 계산 병목
- 입력층의 원핫 표현과 가중치 행렬 Win의 곱 계산
- 은닉층과 가중치 행렬 Wout의 곱 및 Softmax 계층의 계산
Embedding 계층
맥락(원핫 표현)과 MatMul 계층의 가중치 곱하기

- 가중치 매개변수로부터 '단어 ID에 해당하는 행(벡터)'을 추출하는 계층이 Embedding 계층
- Embedding이란 단어 임베딩(word embedding)이라는 요엉에서 유래 - 분산표현
- 자연어 처리 분야에서 단어의 밀집벡터 표현을 단어 임베딩 혹은 단어의 분산 표현(distributed representation)이라 한다.
Embedding 계층 구현
import numpy as np
W = np.arange(21).reshape(7,3) # 2차원 배열 7행 3열
W# Embedding 계층 forward, backward
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0 # dW의 원소를 0으로 덮어쓴다.
dW[self.idx] = dout # 실은 나쁜 예
return None
Embedding 계층의 forward와 backward처리

- backward 구현에는 문제가 있다.
- idx의 원소가 중복될 때 발생. 같은 idx를 할당하게 될 경우 먼저 쓰여진 값을 덮어쓰게 된다.
idx 배열 원소 중 값이 같은 원소가 있다면 dh 를 해당 행에 할당할 때 문제가 생긴다.

- 해결 방법은 '할당'이 아닌 '더하기'를 해야 한다.
역전파 올바르게 구현
def backward(self, dout):
dW, = self.grads
dW[...] = 0 # dW의 원소를 0으로 덮어쓴다.
for i, word_id in enumerate(self, idx):
dW[word_id] += dout[i]
# 혹은
# np.dot.at(dW, self.idx, dout) # dout를 dW의 self.idx행에 더해준다.
return None
출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형






최근댓글