728x90
반응형
CBOW 모델과 확률
- A라는 현상이 일어날 확률을 P(A)라고 한다.
- 동시 확률은 P(A,B)로 쓴다.
- 사후 확률은 P(A|B)로 쓴다.
- 사후 확률은 '사건이 일어난 후의 확률'이다.
- 'B'라는 정보가 주어졌을 때 A가 일어날 확률이라고 해석도 가능하다.

wt-1과 wt+1이 주어졌을 때 타깃이 wt가 될 확률의 수식

- wt-1과 wt+1이 일어난 후 wt가 일어날 확률을 뜻한다.
CBOW 모델의 손실 함수 간결하게 표현

- 음의 로그 기능도(negative log likelihood)라고 한다.
- 샘플 데이터 하나에 대한 손실 함수
말뭉치 전체에 대한 손실 함수

skip-gram 모델
- word2vec은 2개 모델 제안
- CBOW모델
- skip-gram모델
- CBOW에서 다루는 맥락과 타깃을 역전시킨 모델
CBOW 모델과 skip-gram 모델이 다루는 문제

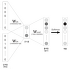
skip-gram 모델의 신경망 구성 예

- skip-gram 모델의 입력층은 하나다.
- 출력층은 맥락의 수만큼 존재한다.
skip-gram 모델 확률 표기

- 'wt'가 주어졌을 때 'wt-1'와 'wt+1'이 동시에 일어날 확률을 뜻한다.
skip-gram 에서는 맥락의 단어들 사이에 관련성이 없다고 가정하고 아래 그림과 같이 분해한다.

교차 엔트로피 오차 적용

말뭉치 전체 확장

- skip-gram 모델은 맥락의 수만큼 추측하기 때문에 그 손실 함수는 각 맥락에서 구한 손실의 총합이어야 한다.
- CBOW 모델은 타깃 하나의 손실을 구한다.
- skip-gram 모델이 더 사용하기 좋다. 정밀도 면에서 결과가 더 좋기 때문
통계기반 vs 추론 기반
- 통계 기반 기법은 말뭉치의 전체 통계로부터 1회 학습해 단어의 분산 표현을 얻는다.
- 추론 기반 기법은 미니배치 학습 - 말뭉치의 일부분씩 학습해 단어의 분산 표현을 얻는다.
단어의 분산 표현을 갱신해야 할 경우
- 통계 기반 기법에서는 계산을 처음부터 다시 해야한다.
- 추론 기반 기법은 매개변수를 다시 학습할 수 있다.
- 이러한 점에서는 추론 기반 기법(word2vec)이 우세하다.
두 기법으로 얻는 단어의 분산 표현이나 정밀도
- 통계 기반 기법에서는 주로 단어의 유사성이 인코딩된다.
- word2vec(특히 skip-gram)에서는 단어의 유사성은 물론, 한층 복잡한 단어 사이의 패턴까지도 파악되어 인코딩된다.
- 이러한 이유 때문에 추론 기반 기법이 더 정확하다고 생각하지만, 단어의 유사성을 정량 평가해본다면 추론 기반과 통계 기반 기법의 우열을 가릴 수 없다.
출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형






최근댓글