728x90
반응형
말뭉차(corpus)
- 대량의 텍스트 데이터
- 자연어 처리 연구나 애플리케이션을 염두에 두고 수집된 텍스트 데이터
- 사람이 쓴 글이므로 사람의 '지식'이 충분히 담겨 있다고 볼 수 있다.
- 문장을 쓰는 방법, 단어를 선택하는 방법, 단어의 의미 등
파이썬으로 말뭉치 전처리
- 유명한 말뭉치 - 위키백과(Wikipedia)와 구글 뉴스(Google News)등의 텍스트 데이터
# 파이썬으로 말뭉치 전처리하기
# 2.3.1
text = 'You say goodbye and I say hello.'
text = text.lower() # 소문자 변환
print("text.lower() : ",text)
text = text.replace('.','.')
print("text.replace : ", text)
words = text.split(' ') # 공백을 기준으로 분할
print("text.split : ", words)
# 문장 단어 목록 형태로 이용
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = wordprint("word_to_id : ",word_to_id)
print("id_to_word : ",id_to_word)
텍스트 데이터(말뭉치)전처리(preprocessing)
- 텍스트 데이터를 단어로 분할하고 그 분할된 다어들을 단어 ID 목록으로 변환하는 일
# 말뭉치 전처리
import numpy as np
def preprocess(text):
text = text.lower() # 소문자 변환
text = text.replace('.','.')
words = text.split(' ')
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_wordtext = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)print("corpus : ",corpus)
print("word_to_id : ",word_to_id)
print("id_to_word : ",id_to_word)
단어의 분산 표현
- RGB(Red/Green/Blue)
- 모든 색을 3가지 성분으로 간결하게 표현가능
- RGB(170,33,22)라면 빨강 계열의 색임을 짐작 가능
- 3차원 벡터로 표현
- 모든 색을 3가지 성분으로 간결하게 표현가능
- '색'을 벡터로 표현하듯 '단어'도 벡터로 표현 가능
- 자연어 처리 분야에서의 '분산 표현(distibutional representation)'
분포 가설(distributional hypothesis)
- '단어의 의미는 주변 단어에 의해 형성된다.'라는 의미
- 단어를 벡터로 표현하는 최근 연구도 대부분 이 가설에 기초
- 단어 자체에는 의미가 없고, 그 단어가 사용된 '맥락(context)'이 의미를 형성한다는 것을 말하고자 한다.
- '맥락'이란 (주목하는 단어)주변에 놓인 단어를 가리킨다.
동시발생 행렬
- 분포 가설에 기초해 단어를 벡터로 나타내는 방법
- 주변 단어를 '세어보는'방법 - '통계기반(statistical based)'기법
# 2.3.4 동시발생 행렬
# 전처리부터
import sys
sys.path.append('..')
import numpy as np
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
print('corpus', corpus)
print('id_to_word ', id_to_word)
# 단어 수 7개

- 윈도우 크기 1이고 단어 ID가 0인 "you"부터 시작하면 "you"의 맥락은 "say"라는 단어 하나뿐이다.
단어 "you"의 맥락에 포함되는 단어의 빈도

- 이를 바탕으로 "you"라는 단어를 [0,1,0,0,0,0,0]이라는 벡터로 표현할 수 있다.
단어 "say"의 맥락에 포함되는 단어의 빈도

- "say" [1,0,1,0,1,1,0] 벡터로 표현 가능
모든 단어 각각의 맥락 빈도

- 표의 각 행은 해당 단어를 표현한 벡터가 된다.
- 표가 행렬의 형태를 띈다는 점에서 동시발생 행렬(co-occurrence matrix)라고 한다.
파이썬 구현
# 동시발생 행렬
C = np.array([
[0,1,0,0,0,0,0],
[1,0,1,0,1,1,0],
[0,1,0,1,0,0,0],
[0,0,1,0,1,0,0],
[0,1,0,1,0,0,0],
[0,1,0,0,0,0,1],
[0,0,0,0,0,1,0], # 동시발생 행렬 구현 단어의 벡터화
], dtype=np.int32)
print('C[0] : ',C[0]) # ID가 0인 단어의 벡터 표현
print('C[4] : ',C[4]) # ID가 4인 단어의 벡터 표현
print('C[word_to_id["goodbye"]] : ', C[word_to_id['goodbye']]) # "goodbye"의 벡터 표현
동시핼렬 자동화 함수
# 말뭉치로부터 동시발생 행렬을 만들어주는 함수
# 자동화
def create_co_matrix(corpus, vocab_size, window_size=1): # 차례로 단어 ID의 리스트, 어휘 수, 윈도우 크기
corpus_size = len(corpus)
co_matrix = np.zeros((vocab_size, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
for i in range(1, window_size + 1):
left_idx = idx - i
right_dix = idx + i
if left_idx >= 0:
left_word_id = corpus[left_idx]
co_matrix[word_id, left_word_id] += 1
if right_idx < corpus_size:
right_word_id = corpus[right_idx]
co_matrix[word_id, right_word_id] += 1
return co_matrix- 먼저 co_matrix를 0으로 채워진 2차원 배열로 초기화 - np.zeros
- 말뭉치의 모든 안어 각각에 대하여 윈도우에 포함된 주변 단어를 세어나간다.
- 왼쪽 끝과 오른쪽 끝 경계를 벗어나지 않는지도 확인한다.
- 말뭉치가 아무리 커지더라도 자동으로 동시발생 행렬을 만들어준다.
벡터 간 유사도
- 벡터의 유사도를 측정하는 방법
- 벡터의 내적이나 유클리드 거리 등
- 단어 벡터의 유사도를 나타낼 때에는 코사인 유사도(cosine similarity)를 자주 이용한다.
코사인 유사도 수식

- 분자에는 벡터의 내적, 분모에는 각 벡터의 노름(norm)이 등장한다.
- 노름은 벡터의 크기를 나타낸 것이다.
- 핵심은 벡터를 정규화하고 내적을 구하는 것이다.
코사인 유사도를 직관적으로 풀면 '두 벡터가 가리키는 방향이 얼마나 비슷한가'이다.
두 벡터의 방향이 완전히 같다면 코사인 유사도가 1이 되며, 완전히 반대라면 -1이 된다.
# 코사인 유사도
def cos_similarity(x, y, eps=1e-8):
mx = x/np.sqrt(np.sum(x**2) + eps) # x의 정규화
my = y/np.sqrt(np.sum(y**2) + eps) # y의 정규화
return np.dot(nx, ny) # 인수로 제로 벡터(원소가 모두 0인 벡터)가 들어오면 0으로 나누기 오류가 발생
# 해결법은 cos_similarity(x, y, eps=1e-8)로 수정import sys
sys.path.append('..')
text = "You say goodbye and I say hello."
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
c0 = C[word_to_id['you']] # 'you' 의 단어 벡터
c1 = C[word_to_id['i']] # 'i'의 단어 벡터
print(cos_similarity(c0,c1))

- 유사도 값은 -1에서 1사이이므로 0.7이면 유사도가 높다고 말할 수 있다.
유사 단어의 랭킹 표시
most_similar(query, word_to_id, id_to_word, word_matrix, top=5)| 인수명 | 설명 |
| query | 검색어(단어) |
| word_to_id | 단어에서 단어 ID로의 딕셔너리 |
| id_to_word | 단어ID에서 단어로의 딕셔너리 |
| word_matrix | 단어 벡터들을 한데 모은 행렬, 각 행에는 대응하는 단어의 벡벡터가 저장되어 있다고 가정한다. |
| top | 상위 몇 개까지 출력할지 설정 |
most_similar()함수
# 유사 단어의 랭킹 표시
def most_similar(query, word_to_id, id_to_word, word_matrix, top=5): # 5개까지
# 검색어 꺼내기
if query not in word_to_id:
print("%s(을)를 찾을 수 없습니다." % query)
return
print('\n[query]' + query)
query_id = word_to_id[query]
query_vec = word_matrix[query_id]
# 코사인 유사도 계산
vocab_size = len(id_to_word)
similarity = np.zeros(vocab_size)
for i in rnage(vocab_size):
similarity[i] = cos_similarity(word_matrix[i], query_vec)
# 코사인 유사도를 기준으로 내림차순으로 출력
count = 0
for i in (-1 * similarity).argsort():
if id_to_word[i] == query:
continue
print(' %s : %s ' %(id_to_word[i], similarity[i]))
count+=1
if count >= top:
return- 검색어의 단어 벡터를 꺼낸다.
- 검색어의 단어 벡터와 다른 모든 단어 벡터와의 코사인 유사도를 각각 구한다.
- 계산한 코사인 유사도 결과를 기준으로 값이 높은 순서대로 출력한다.
argsort()
- 단어의 유사도가 높은 순서로 출력 가능
- 반환값은 배열의 인덱스
import sys
sys.path.append('..')
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
most_similar('you', word_to_id, id_to_word, C , top= 5)
- 'you'와 유사한 단어 상위 5개만 출력
출처 : 밑바닥부터 시작하는 딥러닝2
https://www.hanbit.co.kr/store/books/look.php?p_code=B8950212853
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr

728x90
반응형




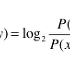


최근댓글