728x90
반응형
하나의 층에 여러 개의 뉴런 사용
- 하나의 층에 여러 개의 뉴런을 사용하면 신경망은 입력층에서 전달되는 특성이 각 뉴런에 모두 전달될 것이다.
- 입력값이 나열된 부분을 입력층이라고 부른다.


- 출력은 (1, 2) 크기의 행렬이다.
- 여러 개의 뉴런을 사용함으로써 가중치가 1개의 열을 가진 벡터가 아닌 2차원 행렬이 되었다는 점이다.
| 첫 번째 특성에 대한 | 두 번째 특성에 대한 | 세 번째 특성에 대한 | |
| 첫 번째 뉴런 가중치 | W11 | W21 | W31 |
| 두 번째 뉴런 가중치 | W21 | W22 | W32 |
- 가중치 행렬의 크기는(입력의 개수, 출력의 개수)로 생각하면 된다.
- 2개의 뉴런을 사용하고 있으므로 출력의 개수는 2개다.
- 하나의 뉴런만 사용한 경우 출력의 개수가 1이므로 가중치는 열 벡터가 된다.
샘플 전체에 대한 수식
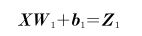
출력을 하나로 모으기
- 위스콘신 유방암 데이터 세트로 우리가 해결한 문제는 악성 종양인지 정상 종양인지 구분하는 경우 이진 분류 문제이므로 각 뉴런에서 출력된 값(z1,z2...zn)을 하나의 뉴런으로 다시 모아야 한다.
- 유방암 데이터 1개의 샘플에 있는 여러 특성의 값을 각 뉴런에 통과시키면 여러 개의 출력값(a1,a2...)이 나오는데, 이 값들 중 하나만 골라 이진 분류에 사용할 수는 없다. 그래서 출력값을 다시 모아 이진 분류 수행할 기준값(z)를 만드는 것이다.


샘플 전체에 대한 행렬 곱셈 표현

행렬 A1의 크기는(전체 샘플 수, 2)이므로 (m, 2)이고 W2의 크기는 (입력의 크기, 출력의 크기) (2,1)이다.
은닉층이 추가된 신경망
구조

입력과 출력은 행렬로 표기한다.

다층 신경망의 개념 정리
- 일반적으로 다층 신경망의 각 층은 2개 이상의 뉴런으로 구성한다.
- 신경망의 은닉층의 뉴런 개수를 2개가 아닌 m으로 늘려 생각해보면 활성화 함수는 뉴런 오른쪽에 작은 원으로 붙여서 표현한다.
- n개의 입력이 m개의 뉴런으로 입력된다.

활성화 함수는 층마다 다를 수 있지만 같은 층에서는 같은 값이어야 한다.
- 은닉층과 출력층에 있는 모든 뉴런에는 활성화 함수가 필요하며 문제에 맞는 활성화 함수를 사용해야 한다.
- 단, 같은 층에 있는 뉴런은 모두 같은 활성화 함수를 사용해야 한다.
- 예) 이진 분류 문제에는 출력층의 활성화 함수로 시그모이드 함수를 사용해야 한다.
모든 뉴런이 연결되어 있으면 완전 연결 신경망이라고 한다.
- 입력층, 은닉층, 은닉층과 출력층 사이의 모든 뉴런들이 연결되어 있으면 완전 연결(fully-connected)신경망이라고 부른다. 예) 그림9
- 완전 연결 신경망은 인공신경망의 한 종류이며, 가장 기본적인 신경망 구조다. 이렇게 뉴런이 모두 연결되어 있는 층을 완전 연결층이라고 한다.
- 다른 신경망의 종류
- 데이터 흐름이 순환되는 순환 신경망
- 정방향으로 데이터가 흐르지만 완전히 연결되어 있지 않은 합성곱 신경망
- 완전 연결 신경망은 다층 퍼셉트론이라고도 부른다. 뉴런들이 빠찜 없이 연결되어 있어 밀집 연결(densely-connected)신경망 또는 층과 층 사이의 흐름이 한쪽 방향으로만 진행되는 특징이 있어 피드 포워드(feed forward)신경망이라고 부르기도 한다.
다층 신경망에 경사 하강법 적용

- 입력 데이터 X와 가중치 W1을 곱하고 절편 b1을 더해 Z1이 된다.
- Z1은 호라성화 함수(시그모이드 함수)를 통과해 A1이 된다. (여기까지가 첫 번째 은닉층)
- 첫 번째 은닉층의 활성화 출력 A1과 출력층의 가중치 W2를 곱하고 절편 b2를 더해 Z2를 만든다.
- 그 다음 Z2는 다시 활성화 함수(시그모이드 함수)를 통과해 A2가 된다. (여기까지 출력층)
- A2의 값을 보고 0.5보다 크면 양성, 그렇지 않으면 음성으로 예측한다.
- 여기서 경사 하강법을 적용하려면 W2와 b2그리고 W1, b1에 대한 손실 함수 L의 도함수를 구해야 한다.
가중치에 대하여 손실 함수 미분(출력층)
- W2에 대한 손실 함수의 미분 연쇄 법칙

신경망에 적용시




도함수 곱하기(출력층)
- -(Y-A2)와 A1은 그냥 곱하면 안된다. 행렬의 크기와 순서에 주의하며 곱해야 한다.
- -(Y-A2)의 행렬 크기는 Y는 (m, 1)이고 A2도 (m,1)크기이므로 (m,1)이다.
A1

- A1의 크기는 (m,2)이고 -(Y-A2)의 크기는 (m,1)이므로 A1을 전치해 -(Y-A2)와 곱해야 한다. W2와 같은(2,1)크기의 그레이디언트 행렬을 얻을 수 있다.

절편에 대하여 손실 함수 미분(출력층)
- 신경망에 절편에 대한 손실 함수의 미분 표시

- Z2를 절편에 대하여 미분하면 1이다. 모든 원소가 1인 벡터 강조하기 위해 1을 볼드로 표기
- 여기서 구한 값 역시 모든 샘플에 대한 그레이디언트의 합이다.
가중치에 대하여 손실 함수 미분(은닉층)
- W1에 대하여 손실 함수 미분
- 연쇄 법칙으로 나타내기


도함수를 곱하기(은닉층)

절편에 대하여 손실 함수를 미분하고 도함수를 곱하기

2개의 층을 가진 신경망 구현하기
- SingleLayer 클래스의 은닉층 부분의 계산을 제외하면 대부분 비슷한 기능을 가지고 있으므로 SingleLayer 클래스를 상송해 DualLayer 클래스를 만들고 필요한 메서드만 재정의
1. SingleLayer 클래스를 상속한 DualLayer 클래스 만들기
- 은닉층의 뉴런 개수를 지정하는 units 매개변수 추가
# 1. SingleLayer 클래스를 상속한 DualLayer 클래스 만들기
class DualLayer(SingleLayer):
def __init__(self, units=10, learning_rate=0.01, l1=0, l2=0):
self.units = units # 은닉층 뉴런 개수
self.w1 = None # 은닉층의 가중치
self.b1 = None # 은닉층의 절편
self.w2 = None # 출력층의 가중치
self.b2 = None # 출력층의 절편
self.a1 = None # 은닉층의 활성화 출력
self.losses = [] # 훈련 손실
self.val_losses = [] # 검증 손실
self.lr = learning_rate # 학습률
self.l1 = l1 # L1 손실 하이퍼파라미터
self.l2 = l2 # L2 손실 하이퍼파라미터
# SingleLayer 클래스는 학습 과정을 이해하기 쉽도록 w_history변수에 가중치 변화를 기록했지만
# DualLayer 클래스에서는 가중치 변화를 기록하지 않는다.2. forpass() 메서드 수정
- forpass() 메서드에서는 은닉층과 출력층의 정방향 계산 수행
# 2. forpass() 메서드 수정
# forpass() 메서드에서는 은닉층과 출력층의 정방향 계산 수행
def forpass(self, w):
z1 = np.dot(x, self.w1) + self.b1 # 첫 번째 층의 선형식을 계산
self.a1 = self.activation(z1) # 활성화 함수 적용
z2 = np.dot(self.a1, self.w2) + self.b2 # 두 번째 층의 선형식 계산
return z2
3. backprop() 메서드 수정
# 3. backprop() 메서드 수정
# 그레이디언트를 계산하는 backprop
# 모델 훈련에서 오차를 역전파하는 역할을 하므로 주의해서 구현
def backprop(self, x, err):
m = len(x) # 샘플 개수
# 출력층의 가중치와 절편에 대한 그레이디언트를 계산한다.
w2_grad = np.dot(self.a1.T, err) / m
b2_grad = np.sum(err) / m
# 시그모이드 함수까지 그레이디언트를 계산한다.
err_to_hidden = np.dot(err, self.w2.T) * self.a1 * (1-self.a1)
# 은닉층의 가중치와 절편에 대한 그레이디언트를 계산
w1_grad = np.dot(x.T, err_to_hidden) / m
b1_grad = np.sum(err_to_hidden, axis=0) /m
return w1_grad, b1_grad, w2_grad, b2_grad

5~6 fit() 메서드 수정
- fit() 메서드는 모델 훈련 담당
- 은닉층과 출력층의 가중치, 절편 초기화 에포크마다 정방향 계산 수행해 오차 계산
- 오차를 역전파해 가중치와 절편의 그레이디언트를 계산
- 손실 계산 누적
- 3개의 작은 메서드로 쪼갬
# 4~5. fit() 메서드 수정
# 모델 훈련 담당
# 은닉층과 출력층의 가중치, 절편 초기화 에포크마다 정방향 계산 수행해 오차 계산
# 오차를 역전파해 가중치와 절편의 그레이디언트를 계산
# 손실 계산 누적
# 3개의 작은 메서드로 쪼갬
def init_weights(self, n_features):
self.w1 = np.ones((n_features, self.units)) # (특성 개수, 은닉층의 크기)
self.b1 = np.zeros(self.units) # 은닉층의 크기
self.w2 = np.ones((self.units, 1))# 은닉층의 크기, 1
self.b2 = 0
6. fit() 메서드의 for문 안에 있는 코드 일부 training() 메서드로 분리
# 6. fit() 메서드의 for문 안에 있는 코드 일부 traning() 메서드로 분리
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
y = y.reshape(-1, 1) # 타깃을 열 벡터로 변경
y_val = y_val.reshape(-1, 1)
m = len(x) # 샘플의 개수 저장
self.init_weights(x.shape[1]) # 은닉층과 출력층의 가중치 초기화
# epochs 만큼 반복
for i in range(epochs):
a = self.training(x, y, m)
# 안전한 계산 위해 클리핑
a = np.clip(a, 1e-10, 1-1e-10)
# 로그 손실과 규제 손실 더해 리스트에 추가
loss = np.sum(-(y*np.log(a) + (1-y)*np.log(1-a)))
self.losses.append((loss + self.reg_loss())/m)
# 검증 세트에 대한 손실 계산
self.update_val_loss(x_val, y_val)
def training(self, x, y, m):
z = self.forpass(x) # 정방향 계산 수행
a = self.activation(z) # 활성화 함수 적용
err = -(y-a) # 오차 계산
# 오차 역전파하여 그레이디언트 계산
w1_grad, b1_grad, w2_grad, b2_grad = self.backprop(x, err)
# 그레이디언트에서 페널티 항의 미분값 빼기
w1_grad += (self.l1 * np.sign(self.w1) + self.l2 *self.w1) /m
w2_grad += (self.l1 * np.sign(self.w2) + self.l2 *self.w2) /m
# 은닉층의 가중치와 절편 업데이트
self.w1 -= self.lr * w1_grad
self.b1 -= self.lr * b1_grad
# 출력층의 가중치와 절편 업데이트
self.w2 -= self.lr * w2_grad
self.b2 -= self.lr * b2_grad
return a
# 정방향 계산과 그레이디언트를 업데이트하는 코드를 training() 메서드로 옮겼다.
# 이 메서드는 훈련 데이터 x,y와 훈련 샘플의 개수 m을 매개변수로 받고 마지막 출력층의 활성화 출력 a를 반환한다.
7. reg_loss() 메서드 수정
- reg_loss() 메서드는 은닉층과 출력층의 가중치에 대한 L1, L2 손실을 계산한다.
# 7. reg_loss() 메서드 수정하기
# reg_loss() 메서드는 은닉층과 출력층의 가중치에 대한 L1,L2 손실을 계산한다.
def reg_loss(self):
# 은닉층과 출력층의 가중치에 규제를 적용
return self.l1 * (np.sum(np.abs(self.w1) + np.sum(np.abs(self.w2)))) + \
self.l2 / 2 * (np.sim(self.w1**2) + np.sum(self.w2**2))
모델 훈련하기
class DualLayer(SingleLayer):
def __init__(self, units=10, learning_rate=0.1, l1=0, l2=0):
self.units = units # 은닉층의 뉴런 개수
self.w1 = None # 은닉층의 가중치
self.b1 = None # 은닉층의 절편
self.w2 = None # 출력층의 가중치
self.b2 = None # 출력층의 절편
self.a1 = None # 은닉층의 활성화 출력
self.losses = [] # 훈련 손실
self.val_losses = [] # 검증 손실
self.lr = learning_rate # 학습률
self.l1 = l1 # L1 손실 하이퍼파라미터
self.l2 = l2 # L2 손실 하이퍼파라미터
def forpass(self, x):
z1 = np.dot(x, self.w1) + self.b1 # 첫 번째 층의 선형 식을 계산합니다
self.a1 = self.activation(z1) # 활성화 함수를 적용합니다
z2 = np.dot(self.a1, self.w2) + self.b2 # 두 번째 층의 선형 식을 계산합니다.
return z2
def backprop(self, x, err):
m = len(x) # 샘플 개수
# 출력층의 가중치와 절편에 대한 그래디언트를 계산합니다.
w2_grad = np.dot(self.a1.T, err) / m
b2_grad = np.sum(err) / m
# 시그모이드 함수까지 그래디언트를 계산합니다.
err_to_hidden = np.dot(err, self.w2.T) * self.a1 * (1 - self.a1)
# 은닉층의 가중치와 절편에 대한 그래디언트를 계산합니다.
w1_grad = np.dot(x.T, err_to_hidden) / m
b1_grad = np.sum(err_to_hidden, axis=0) / m
return w1_grad, b1_grad, w2_grad, b2_grad
def init_weights(self, n_features):
self.w1 = np.ones((n_features, self.units)) # (특성 개수, 은닉층의 크기)
self.b1 = np.zeros(self.units) # 은닉층의 크기
self.w2 = np.ones((self.units, 1)) # (은닉층의 크기, 1)
self.b2 = 0
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
y = y.reshape(-1, 1) # 타깃을 열 벡터로 바꿉니다.
y_val = y_val.reshape(-1, 1)
m = len(x) # 샘플 개수를 저장합니다.
self.init_weights(x.shape[1]) # 은닉층과 출력층의 가중치를 초기화합니다.
# epochs만큼 반복합니다.
for i in range(epochs):
a = self.training(x, y, m)
# 안전한 로그 계산을 위해 클리핑합니다.
a = np.clip(a, 1e-10, 1-1e-10)
# 로그 손실과 규제 손실을 더하여 리스트에 추가합니다.
loss = np.sum(-(y*np.log(a) + (1-y)*np.log(1-a)))
self.losses.append((loss + self.reg_loss()) / m)
# 검증 세트에 대한 손실을 계산합니다.
self.update_val_loss(x_val, y_val)
def training(self, x, y, m):
z = self.forpass(x) # 정방향 계산을 수행합니다.
a = self.activation(z) # 활성화 함수를 적용합니다.
err = -(y - a) # 오차를 계산합니다.
# 오차를 역전파하여 그래디언트를 계산합니다.
w1_grad, b1_grad, w2_grad, b2_grad = self.backprop(x, err)
# 그래디언트에서 페널티 항의 미분 값을 뺍니다
w1_grad += (self.l1 * np.sign(self.w1) + self.l2 * self.w1) / m
w2_grad += (self.l1 * np.sign(self.w2) + self.l2 * self.w2) / m
# 은닉층의 가중치와 절편을 업데이트합니다.
self.w1 -= self.lr * w1_grad
self.b1 -= self.lr * b1_grad
# 출력층의 가중치와 절편을 업데이트합니다.
self.w2 -= self.lr * w2_grad
self.b2 -= self.lr * b2_grad
return a
def reg_loss(self):
# 은닉층과 출력층의 가중치에 규제를 적용합니다.
return self.l1 * (np.sum(np.abs(self.w1)) + np.sum(np.abs(self.w2))) + \
self.l2 / 2 * (np.sum(self.w1**2) + np.sum(self.w2**2))1. 다층 신경망 모델 훈련하고 평가
#1. 다층 신경망 모델 훈련하고 평가
# L2 규제는 0.01만큼, 에포크는 20,000번 지정
dual_layer = DualLayer(l2 = 0.01)
dual_layer.fit(x_train_scaled, y_train, x_val = x_val_scaled, y_val=y_val, epochs=20000)
dual_layer.score(x_val_scaled, y_val)
2. 훈련 손실과 검증 손실 그래프 분석
# 2. 훈련 손실과 검증 손실 그래프 분석
plt.ylim(0, 0.3)
plt.plot(dual_layer.losses)
plt.plot(dual_layer.val_losses)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss', ' val_loss'])
plt.show()
# 손실 그래프가 이전보다 천천히 감소하는 이유는 SingleLayer보다
# 가중치의 개수가 훨씬 많아져 학습하는데 시간이 오래 걸리기 때문
# 위스콘신 유방암 데이터의 특성이 30개이므로 SingleLayer 클래스를 사용했을 때는 가중치 30개와 절편 1개가 필요하다.
# 은닉층 뉴런이 10개였으므로 30 * 10개의 가중치와 10개의 절편이 필요하고
# 출력층 역시 10개의 가중치와 1개의 절편이 필요하다.
# DualLayer 모델은 총 321개의 가중치를 학습해야 한다.
가중치 초기화 개선
1. 가중치 초기화를 위한 init__weights() 메서드 수정하기
- RandominitNetwork 클래스 만들고 가중치 초기화하는 init__weights() 메서드만 고치기
# 1. 가중치 초기화를 위한 init__weights() 메서드 수정하기
# RandomInitNetwork 클래스 만들고 가중치 초기화하는 init__weights() 메서드만 고치기
class RandomInitNetwork(DualLayer):
def init_weights(self, n_features):
np.random.seed(42)
self.w1 = np.random.normal(0, 1, (n_features, self.units)) #특성 개수, 은닉층의 크기
self.b1 = np.zeros(self.units) # 은닉층의 크기
self.w2 = np.random.normal(0, 1, (self.units, 1)) # (은닉층의 크기, 1)
self.b2 = 0
2. 객체 생성 후 모델 훈련 시키기
# 2. 객체 생성 후 모델 훈련 시키기
random_init_net = RandomInitNetwork(l2 =0.01)
random_init_net.fit(x_train_scaled, y_train, x_val=x_val_scaled,
y_val=y_val, epochs=500)
plt.plot(random_init_net.losses)
plt.plot(random_init_net.val_losses)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss','val_loss'])
plt.show()
# 손실 함수가 감소하는 곡선이 매끄럽다,.
728x90
반응형








최근댓글