728x90
반응형
모델의 성능 평가를 위한 훈련 세트와 테스트 세트
- 훈련된 모델의 실전 성능을 일반화 성능(generalization performance)라고 부른다.
- 올바르게 모델의 성능 측정
- 훈련 데이터 세트를 두 덩어리로 나누기
- 하나는 훈련에 사용하고 하나는 테스트에 사용하기
- 각각 덩어리를 훈련 세트(training set)와 테스트 세트(test set)라고 부른다.
훈련 데이터 세트를 훈련 세트와 테스트 세트로 나누는 규칙
- 훈련 데이터 세트를 나눌 때는 테스트 세트보다 훈련 세트가 많아야 한다.
- 훈련 데이터 세트를 나누기 전에 양성, 음성 클래스가 훈련 세트나 테스트 세트의 어느 한쪽에 몰리지 않도록 골고루 섞어야 한다.
훈련 세트와 테스트 세트로 나누기
- 양성, 음성 클래스가 훈련 세트와 테스트 세트에 고르게 분포하도록 만들어야 한다.
- 예) cancer 데이터 세트를 보면 양성 클래스와 음성 클래스의 샘플 수가 각각 212, 357개다. 이 클래스 비율이 훈련 세트와 테스트 세트에도 그대로 유지되어야 한다.
1. train_test_split() 함수로 훈련 데이터 세트 나누기
- sklearn.model_selection 모듈에서 train_test_split(0 함수를 임포트 한다.
- 사이킷런의 train_test_split() 함수는 기본적으로 입력된 훈련 데이터 세트를 훈련 세트 75%, 테스트 세트 25% 비율로 나눠준다.
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x, y ,stratify=y, test_size=0.2, random_state=42)
# stratify = y
# stratify는 훈련 데이터를 나눌 때 클래스 비율을 동일하게 만든다. train_test_split() 함수는 기본적으로 데이터를 나누기 전에
# 섞지만 일부 클래스 비율이 불균형한 경우 stratify를 y로 지정해야 한다.
# test_size = 0.2
# train_test.split() 함수는 기본적으로 훈련 데이터 세트를 7.5 : 2.5 비율로 나눈다. 하지만 필요한 경우 이 비율을 조절하고 싶을 때도 있다.
# 여기서는 입력된 데이터 세트의 20%를 테스트 세트로 나누기 위해 test_size를 0.2로 조정
# random_state = 42
# train_test_split() 함수는 무작위로 데이터 세트를 섞은 다음 나눈다. 이 책에서는 섞은 다음 나눈 결과가 항상 일정하도록 random_state 매개변수에 난수 초깃값 42를 지정
# 실전에서는 사용할 필요가 없다
- stratify = y - 훈련 데이터를 나눌 때 클래스 비율을 동일하게 만듦. train_test_split() 함수는 기본적으로 데이터를 누니기 전에 섞지만 일부 클래스 비율이 불균형한 경우 stratify를 y로 지정해야 한다.
- test_size = 0.2 - split() 함수는 기본적으로 훈련 데이터 세트를 7.5 : 2.5비율로 나눈다. 하지만 이 비율을 조절하고 싶을 때 test_size를 사용한다. 여기서는 입력 데이터 세트의 20%를 데이터 세트로 나누기 위해 사용했다.
- random_state = 42 - split()함수는 무작위로 데이터 세트를 섞은 다음 나눈다. 실전에서는 사용할 필요가 없다.
2. 결과 확인
# 결과 확인하기
print("x_train.shape : ",x_train.shape, "x_test.shape : ",x_test.shape)
# 4대 1 비율로 나눠짐

3. unique() 함수로 훈련 세트 타깃 확인하기
# unique()함수로 훈련 세트 타깃 확인
np.unique(y_train, return_counts=True) # 클래스 비율 그대로 유지
# 양성 클래스가 음성 클래스보다 1.7배 정도 많다.

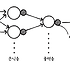
로지스틱 회귀 구현하기
# 로지스틱 회귀 구현하기
class LogisticNeuron:
def __init__(self):
self.w = None
self.b = None
def forpass(self, x):
z = np.sum(x * self.w) + self.b # 직선 방ㅈㅇ식 계싼
return z
def backprop(self, x, err):
w_grad = x * err # 가중치에 대한 그레디언트 계산
b_grad = 1 * err # 절편에 대한 그레디언트 계산
# __init__ 메서드에서는 입력 데이터의 특성이 많아 가중치와 절편을 미리 초기화 하지 않는다.
# 가중치는 나중에 입력 데이터를 보고 특성 개수에 맞게 결정한다.
# forpass() 메서드에 넘파이 함수 사용 np.sum() x*self.w에서 x와 w는 1차원 넘파이 배열인데 넘파이 배열에 사칙연산 적용시 자동으로
# 배열의 요소끼리 계산한다.
훈련하는 메서드 구현하기
# 훈련하는 메서드 구현하기
# 훈련 수행 fit()메서드 구현
def fit(self, x, y, epochs=100):
self.w = np.ones(x.shape[1]) # 가중치 전부 1로 초기화
self.b = 0 # 절편
for i in range(epochs): #epochs만큼 반복
for x_i,y_i in zip(x, y): # 모든 샘플에 대해 반복
z = self.forpass(x_i) #정방향 계산
a = self.activation(z) # 활성화 함수 적용
err = -(y_i - a)# 오차 계산
w_grad, b_grad = self.backprop(x_i, err) # 역방향 계산
self.w -= w.grad # 가중치 업데이트
self.b -= b.grad # 절편 업데이트
activation() 메서드 구현
# activation() 메서드 구현
# activation() 메서드에서는 시그모이드 함수가 사용되어야 한다. np.exp()사용시 간단히 만든다.
# np.exp = 자연 상수의 지수 함수 계산
def activation(self, z):
a = 1/(1+np.exp(-z)) # 시그모이드 계산
return a
예측하는 메서드 구현
- predict() 메서드 구현 x가 2차원 배열로 전달된다고 가정
- 리스트 내포 - 대괄호 안에 for문을 삽입해 새 리스트를 만드는 간결한 문법
# 예측하는 메서드 구현
# 예측값 계산시 forpass() 메서드 사용
# 새로운 샘플에 대한 예측값 계산해주는 메서드 predict() 메서드 만들기
# 매개변수 값으로 입력값 x가 2차원 배열로 전달된다고 가정
def predict(self, x):
z = [self.forpass(x_i) for x_i in x] # 선형 함수 적용 , 리스트 내포 문법
a = self.activation(np.array(z)) # 활성화 함수 적용
return a > 0.5 # 계단 함수 적용
총합
# 구현 종합
class LogisticNeuron:
def __init__(self):
self.w = None
self.b = None
def forpass(self, x):
z = np.sum(x*self.w) + self.b # 직선 방정식 계산
return z
def backprop(self, x, err):
w_grad = x * err # 가중치에 대한 그레디언트 계산
b_grad = 1 * err # 절편에 대한 그레디언트 계산
return w_grad, b_grad
def activation(self, z):
z = np.clip(z, -100, None) # 안전한 np.exp()계산 위해서
a = 1/(1+np.exp(-z)) # 시그모이드 계산
return a
def fit(self, x, y, epochs=100):
self.w = np.ones(x.shape[1]) # 가중치 전부 1로 초기화
self.b = 0 # 절편
for i in range(epochs): #epochs만큼 반복
for x_i,y_i in zip(x, y): # 모든 샘플에 대해 반복
z = self.forpass(x_i) #정방향 계산
a = self.activation(z) # 활성화 함수 적용
err = -(y_i - a)# 오차 계산
w_grad, b_grad = self.backprop(x_i, err) # 역방향 계산
self.w -= w_grad # 가중치 업데이트
self.b -= b_grad # 절편 업데이트
def predict(self, x):
z = [self.forpass(x_i) for x_i in x] # 선형 함수 적용 , 리스트 내포 문법
a = self.activation(np.array(z)) # 활성화 함수 적용
return a > 0.5 # 계단 함수 적용
로지스틱 회귀 모델 훈련시키기
# 로지스틱 회귀 모델 훈련시키기
neuron = LogisticNeuron() # 객체 생성
neuron.fit(x_train, y_train)
정확도 평가
# 모델 정확도 평가
np.mean(neuron.predict(x_test) == y_test)
# predit() 메서드 반환값은 True나 False로 채워진(m,) 크기의 배열이고 y_test는 0또는 1로 채워진(m,) 크기의 배열이므로 바로 비교각 가능하다.
# np.mean()함수는 매개변수 값으로 전달한 비교문결과(넘파이 배열)의 평균을 계산한다.
# 계산 결과 0.8245...~ 는 올바르게 예측한 샘플의 비율이 된다.
# 이를 정확도(accuracy) 라고 한다.
728x90
반응형




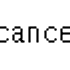
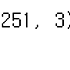
최근댓글